如何设计一个短url地址服务?
什么是短URL
把URL缩短,用于为长URL创建更短的别名,我们称这些缩短的别名为 「短链接」
当用户点击这些短链接时,会被重定向到原始URL,短链接在显示、打印、发送消息或发推时可以节省大量空间;此外,用户也不太可能输入错误的短url。
例如,如果我们通过 TinyURL 缩短这个页面:
可以得到:
缩短URL的大小接近实际URL的三分之一。
URL缩短用于优化跨设备的链接,跟踪单个链接以分析受众和活动表现,以及隐藏关联的原始URL。
那么我们应该如何设计这样的服务呢?像TinyURL
需求和目标
首先我们应该从一开始就明确要求,考虑系统的具体范围。
我们的网址缩短系统应符合一些规定。
功能需求:
- 给定一个URL,我们的服务应该生成一个更短且唯一的URL别名,这被称为短链接。这个链接应该足够短,便于复制和粘贴到应用程序中。
- 当用户访问短链接时,我们的服务应该将他们重定向到原始链接。
- 用户应该能够选择一个定制的短链接为他们的URL。
- 链接将在一个默认时间间隔之后过期,用户应该能够指定过期时间。
非功能性需求:
- 系统应该是高可用的。因为如果我们的服务停止,所有的 URL重定向 都将开始失败。
- URL重定向应该以最小的延迟实时发生。
- 缩短的链接不应该是可猜测的(不可预测的)。
扩展要求:
- 分析;例如,发生了多少次重定向?
- 我们的服务也应该可以被其他服务通过REST api访问。
容量估算与约束
我们的系统将会有大量的读取,与新的URL缩短相比,将会有大量的重定向请求。让我们假设读和写的比率是100:1。
流量估计:假设,我们每个月将有5亿个新的URL缩短,以100:1的读/写比率,我们可以预期在同一时期有50B的重定向:
「100 * 500 => 50b」
每秒新增url缩短:
考虑到100:1的读写比率,每秒url重定向为:
100 * 200 url /s = 20K/s
存储估计:假设我们将每个URL缩短请求(以及相关的缩短链接)存储5年,由于我们预计每个月有5亿个新url,我们预计存储的对象总数将是300亿个:
5亿 * 5年 * 12个月 = 300亿
让我们假设每个存储的对象大约为500字节(这只是一个粗略的估计——我们将在后面深入研究)。我们将需要15TB的总存储空间:
300亿 * 500字节 = 15tb
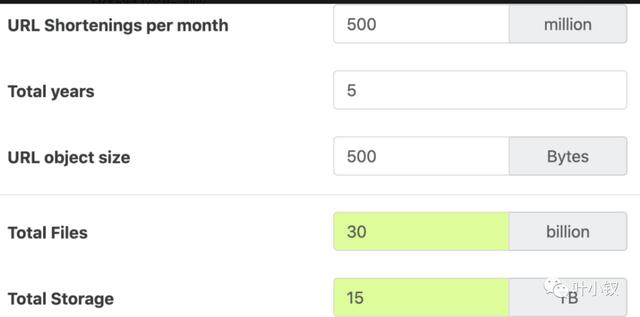
带宽 估计:对于写请求,因为我们预计每秒钟有200个新的url,所以我们服务的总传入数据将是每秒100KB:
200 * 500字节 = 100kb /s
对于读请求,由于我们预计每秒钟有20K个url重定向,我们服务的总输出数据将是每秒10MB:
20K * 500字节 = ~ 10mb /s
内存估计:如果我们想缓存一些经常被访问的热门url,我们需要多少内存来存储它们?如果我们遵循2-8原则,即20%的url产生80%的流量,我们希望缓存这20%的热url。
由于我们每秒有2万次请求,我们每天将收到17亿次请求:
20K * 3600秒 * 24小时 = ~ 17亿
为了缓存这些请求的20%,我们将需要170GB的内存。
0.2 * 17亿 * 500字节 = ~170GB
这里需要注意的一点是,由于会有很多重复的请求(相同的URL),因此,我们的实际内存使用将小于170GB。
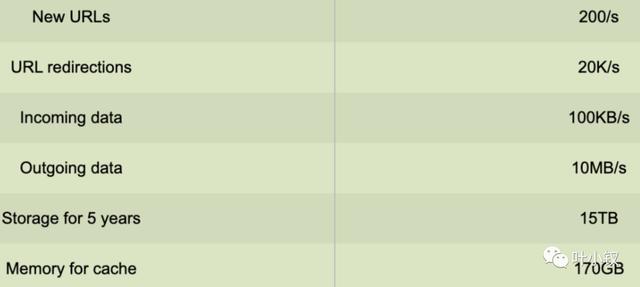
高水平估计:假设每月新增5亿url,读写比例为100:1,以下是我们服务的高水平估计总结:
系统api设计
一旦我们确定了需求,定义系统api总是一个好主意,明确声明系统所期望的内容。
我们可以使用 SOAP 或 REST api来公开服务的功能。下面是创建和删除url的api的定义:
createURL(api_dev_key, original_url, custom_alias=无,user_name=无,expire_date=无)
参数:
api_dev_key (string):注册帐户的API开发人员密钥。这将用于根据用户分配的配额限制用户;
original_url (string):需要缩短的原始URL;
custom_alias (string): URL的可选自定义键。
user_name (string):可选用于编码的用户名。
expire_date (string):可选的缩短URL的过期日期。
返回:(string)一个成功的插入返回缩短的URL;否则,它返回一个错误代码。
deleteURL (api_dev_key url_key)
其中“url_key”是表示要检索的缩短URL的 字符串 ,成功删除将返回“URL已删除”。
我们如何发现和防止滥用?恶意用户可以通过消耗当前设计中的所有URL键来让我们用尽?
为了防止滥用,我们可以通过api_dev_key限制用户。每个api_dev_key可以被限制在一定数量的URL创建和重定向每一段时间(可以为每个用户的键设置不同的持续时间)。
数据库设计
在面试的早期阶段定义DB模式将有助于理解不同组件之间的数据流,并在随后指导数据分区。
关于我们将要存储的数据的性质的几点观察:
- 我们需要存储数十亿条记录。
- 我们存储的每个对象都很小(小于1K)。
- 记录之间没有关系——除了存储哪个用户创建了URL之外。
- 我们的服务是读多的。
数据库结构
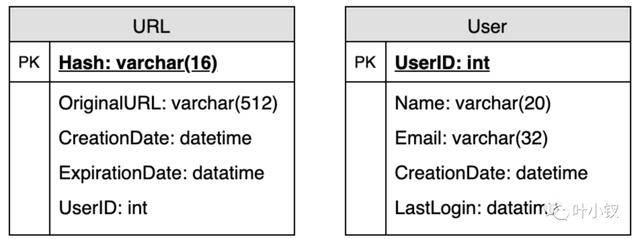
我们需要两个表,一个用于存储关于URL映射的信息,另一个用于存储创建短链接的用户数据:
我们应该使用什么样的数据库?因为我们预期存储数十亿行,而且我们不需要使用对象之间的关系——像 DynamoDB 这样的 NoSQL 存储, Cassandra 或Riak是更好的选择。
NoSQL选择也更容易扩展。详情请参阅 SQL vs NoSQL。
系统设计和算法
这里我们要解决的问题是,如何为给定的URL生成一个简短且唯一的键。
在第1节的TinyURL示例中,缩写URL是“”。这个URL的最后七个字符是我们想要生成的短键,我们将在这里探索两种解决方案:
a.编码实际URL
我们可以计算给定URL的唯一哈希值(例如, MD5 或 SHA256 等),然后可以对散列进行编码以显示。
这种编码可以是base36 ([a-z,0-9])或base62 ([a-z, a-z, 0-9]),如果我们加上’ + ‘和’ / ‘,我们可以使用Base64编码。
一个合理的问题是,短键的长度是多少?6个、8个还是10个字符?
使用base64编码,一个6个字母长的键将产生64^6 = ~ 687亿可用字符串,一个8个字母长的键将产生64^8 = ~281万亿可用字符串。
对于68.7B唯一的字符串,让我们假设六个字母的键就足以满足我们的系统。
如果我们使用MD5算法作为我们的哈希函数,它将产生一个128位的哈希值。在base64编码之后,我们将得到一个超过21个字符的字符串(因为每个base64 字符编码 了6位的哈希值)。
现在我们每个短键只有8个字符的空间,那么我们如何选择我们的键呢?我们可以取前6(或8)个字母作为密钥。这可能导致键重复,为了解决这个问题,我们可以从 编码 字符串中选择一些其他字符或交换一些字符。
我们的解决方案有哪些不同的问题?我们的编码方案有以下几个问题:
- 如果多个用户输入相同的URL,他们可以得到相同的缩短URL,这是不可接受的。
- 如果部分URL是URL编码的呢?例如,和除了URL编码之外都是相同的。
问题的解决方法:
我们可以在每个输入URL后面附加一个递增的序列号,使其惟一,然后生成它的哈希值。
不过,我们不需要将这个序列号存储在数据库中,这种方法的可能问题可能是不断增加的序列号。能溢出吗?增加序列号也会影响服务的性能。
另一种解决方案是将用户id(应该是唯一的)附加到输入URL后面,但如果用户没有登录,我们就必须要求用户选择惟一键。即使在这之后,如果有冲突,我们必须不断生成一个键,直到我们得到一个唯一的。

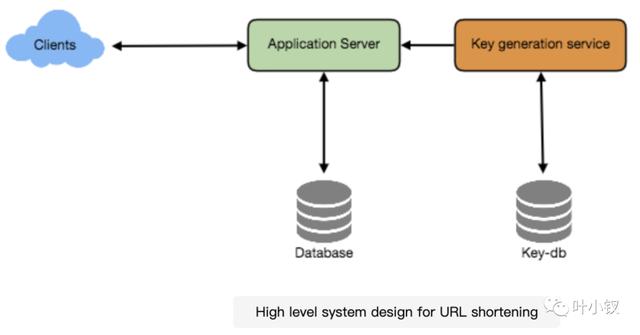
b.离线生成密钥
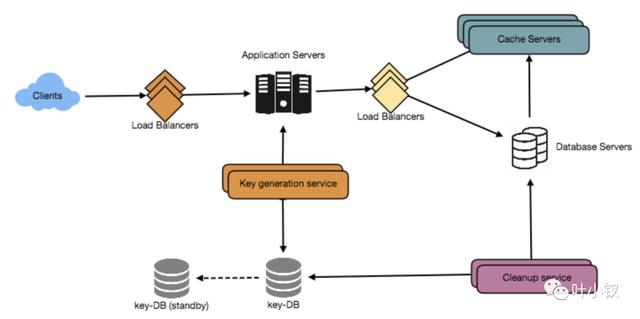
我们可以有一个独立的密钥生成服务(KGS),它预先生成随机的六个字母的字符串,并将它们存储在数据库中(我们称之为Key – db),每当我们想要缩短一个URL时,我们只需要获取一个已经生成的键并使用它。
这种方法将使事情变得非常简单和快速。我们不仅不用对URL进行编码,而且不必担心重复或冲突。KGS将确保插入key-DB的所有密钥是唯一的。
并发性会导致问题吗?一旦使用了一个键,就应该在数据库中标记它,以确保它不会得到重用。如果有多个服务器同时读取键值,我们可能会遇到这样的情况:
两个或多个服务器试图从数据库读取相同的键值,我们如何解决这个并发问题?
服务器可以使用KGS读取/标记数据库中的密钥,KGS可以使用两个表来存储键:
一个用于尚未使用的键,另一个用于所有已使用的键。只要KGS向其中一个服务器提供密钥,它就可以将密钥移动到使用的密钥表中。KGS总是可以在内存中保存一些密钥,以便在服务器需要时快速提供它们。
为了简单起见,只要KGS将一些键加载到内存中,它就可以将它们移动到使用的键表中。这确保每个服务器获得唯一的密钥。如果KGS在将所有加载的键分配给某个服务器之前死亡,我们将浪费这些键——考虑到我们拥有的键的数量巨大,这是可以接受的。
KGS还必须确保不会向多个服务器提供相同的密钥。为此,它必须同步(或锁定)保存键的数据结构,然后从该结构中删除键并将它们交给服务器。
key-DB的大小是多少?使用base64编码,我们可以生成68.7B唯一的6个字母的密钥。如果我们需要一个字节来存储一个字母数字字符,我们可以将所有这些键存储在:
6个字符(每个键) * 68.7B(唯一键) = 412 GB。
KGS不是 单点故障 吗?是的。
为了解决这个问题,我们可以建立一个备用的KGS副本,当主服务器失效时,备用服务器可以接管生成并提供密钥。
每个应用服务器可以缓存key-DB中的一些键吗?是的,这肯定能加快速度。尽管在本例中,如果应用程序服务器在使用所有键之前死亡,我们最终将失去这些键。这是可以接受的,因为我们有68B唯一的六个字母的钥匙。
如何执行键查找?我们可以在数据库中查找键来获得完整的URL。如果它出现在数据库中,发出一个“HTTP 302重定向”状态回传给浏览器,在请求的“位置”字段中传递存储的URL。如果该密钥在我们的系统中不存在,则发出“HTTP 404 not Found”状态或将用户重定向回主页。
我们应该对自定义别名施加大小限制吗?我们的服务支持自定义别名。用户可以选择任何他们喜欢的“键”,但提供自定义别名不是强制性的。
然而,对自定义别名施加大小限制是合理的(而且通常是可取的),以确保我们拥有一致的URL数据库。让我们假设用户可以为每个客户键指定最多16个字符(如上面的数据库模式所示):
数据分区和复制
为了扩展我们的数据库,我们需要对它进行分区,以便它能够存储关于数十亿个url的信息。我们需要提出一种分区方案,将我们的数据划分并存储到不同的DB服务器中。
a.基于范围的分区
我们可以根据哈希键的首字母将url存储在单独的分区中。因此,我们将所有以字母“A”(和“A”)开头的url保存在一个分区中,将那些以字母“B”开头的url保存在另一个分区中,以此类推。这种方法称为基于范围的分区。
我们甚至可以将某些不太经常出现的字母组合到一个数据库分区中。我们应该提出一个静态分区方案,这样我们就可以始终以一种可预测的方式存储/查找URL。
这种方法的主要问题是:它可能导致不平衡的DB服务器。
例如,我们决定将所有以字母’ E ‘开头的url放入一个DB分区中,但是后来我们意识到我们有太多以字母’ E ‘开头的url。
b.基于哈希的分区
在这个方案中,我们获取存储对象的哈希值,然后根据哈希值计算要使用哪个分区。
在本例中,我们可以采用“键”或短链接的哈希值来确定存储数据对象的分区。
我们的哈希函数将随机地将url分配到不同的分区中(例如,我们的哈希函数总是可以将任何“键”映射到[1…256]之间的一个数字),而这个数字将代表我们存储对象的分区。
这种方法仍然会导致分区的重载,这可以通过使用一致的哈希来解决。
缓存
我们可以缓存经常被访问的url。我们可以使用一些现成的解决方案,比如:
Memcached ,它可以用它们各自的哈希值存储完整的url。应用服务器在访问后端存储之前,可以快速检查缓存是否具有所需的URL。
我们应该有多少缓存内存?我们可以从每天流量的20%开始,根据客户的使用模式,我们可以调整需要多少缓存服务器。
如上所述,我们需要170GB的内存来缓存20%的日常流量。由于现在的服务器可以拥有256GB的内存,我们可以很容易地将所有缓存放入一台机器中。或者,我们可以使用几个较小的服务器来存储所有这些热url。
哪种cache逐出策略最适合我们的需求?当缓存是满的,我们想用一个更新/更热的URL替换一个链接,我们应该如何选择?最近最少使用(Least Recently Used, LRU )对于我们的系统来说是一个合理的策略。
在此策略下,我们首先丢弃最近最少使用的URL。我们可以使用一个链接哈希图或类似的数据结构来存储我们的url和哈希表,它也会跟踪最近被访问的url。
为了进一步提高效率,我们可以复制缓存服务器来在它们之间分配负载。
如何更新每个缓存副本?每当缓存丢失时,我们的服务器就会碰到后端数据库,每当发生这种情况时,我们可以更新缓存并将新条目传递到所有缓存副本,每个副本都可以通过添加新条目来更新其缓存。
如果副本已经拥有该条目,则可以忽略它。

负载均衡
我们可以在系统的三个地方添加一个负载均衡层:
- 客户端和应用服务器之间
- 在应用程序服务器和 数据库服务器 之间
- 应用服务器和缓存服务器之间
最初,我们可以使用简单的 轮询 方法,在后端服务器之间平均分配传入的请求。这个LB实现起来很简单,而且不引入任何开销。这种方法的另一个好处是,如果服务器死亡,LB将把它从轮换中取出,并停止向它发送任何流量。
Round Robin LB的一个问题是我们没有考虑服务器负载。如果服务器负载过重或运行缓慢,LB将不会停止向该服务器发送新请求。
要处理这个问题,可以放置一个更智能的LB解决方案,它可以周期性地查询后端服务器的负载,并据此调整流量。
清除或DB清理
条目应该永远存在还是应该被清除?如果达到了用户指定的过期时间,该链接会发生什么?
如果我们选择主动搜索过期链接并删除它们,这将给我们的数据库带来很大的压力。相反,我们可以慢慢地删除过期的链接,并进行惰性清理。我们的服务将确保只有过期的链接将被删除,尽管一些过期的链接可以存活更长时间,但永远不会返回给用户。
当用户试图访问一个过期的链接时,我们可以删除该链接并返回一个错误给用户。一个单独的清理服务可以定期运行,从我们的存储和缓存中删除过期的链接。此服务应该是非常轻量级的,并且只能在预期用户流量较低时调度运行。
我们可以为每个链接设置一个默认过期时间(例如,两年)。
在移除一个过期的链接后,我们可以把key放回key- db中以进行重用。
我们是否应该删除一段时间内(比如6个月)未被访问的链接?这可能很棘手。由于存储变得越来越便宜,我们可以决定永远保持链接。
特殊场景考虑
短URL被使用了多少次,用户位置是什么,等等?我们如何存储这些统计数据?如果它是每个视图上更新的DB行的一部分,当一个流行的URL被大量并发请求攻击时会发生什么?
一些值得跟踪的统计数据:访问者的国家,访问的日期和时间,点击的网页,浏览器,或页面被访问的平台。
安全与权限
用户是否可以创建私有URL或允许特定的一组用户访问URL?
我们可以将权限级别(公有/私有)与每个URL存储在数据库中。我们还可以创建一个单独的表来存储具有查看特定URL权限的userid。如果用户没有权限并试图访问URL,我们可以返回一个错误(HTTP 401)。
假设我们将数据存储在一个像Cassandra这样的NoSQL宽列数据库中,表存储权限的键将是“ Hash ”(或KGS生成的“键”)。这些列将存储那些有权限查看URL的用户的userid。
原文地址:
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24