PHP中pack、unpack的详细用法
pack
string pack ( string $format [, mixed $args [, mixed $... ]] )
该函数用来将对应的参数( $args )打包成二进制字符串。
其中第一个参数$format,有如下选项(可选参数很多,后面会选几个常用的讲解):
|
Code |
Description |
|
a |
以NUL字节填充字符串空白 |
|
A |
以SPACE(空格)填充字符串 |
|
h |
十六进制字符串,低位在前 |
|
H |
十六进制字符串,高位在前 |
|
c |
有符号字符 |
|
C |
无符号字符 |
|
s |
有符号短整型(16位,主机字节序) |
|
S |
无符号短整型(16位,主机字节序) |
|
n |
无符号短整型(16位,大端字节序) |
|
v |
无符号短整型(16位,小端字节序) |
|
i |
有符号整型(机器相关大小字节序) |
|
I |
无符号整型(机器相关大小字节序) |
|
l |
有符号长整型(32位,主机字节序) |
|
L |
无符号长整型(32位,主机字节序) |
|
N |
无符号长整型(32位,大端字节序) |
|
V |
无符号长整型(32位,小端字节序) |
|
q |
有符号长长整型(64位,主机字节序) |
|
Q |
无符号长长整型(64位,主机字节序) |
|
J |
无符号长长整型(64位,大端字节序) |
|
P |
无符号长长整型(64位,小端字节序) |
|
f |
单精度浮点型(机器相关大小) |
|
d |
双精度浮点型(机器相关大小) |
|
x |
NUL字节 |
|
X |
回退一字节 |
|
Z |
以NUL字节填充字符串空白(new in PHP 5.5) |
|
@ |
NUL填充到绝对位置 |
这么多参数看下来,我第一次是真心懵逼了,大部分说明都很好理解,但是其中的主机、大端、小端等字节序是什么鬼呢?接下里的内容比较枯燥,但必须理解才行,坚持吧。
字节序是什么?
就是字节的顺序,说白了就是多字节数据的存放顺序(一个字节显然不需要顺序)。
比如 A 和 B 分别对应的二进制表示为 0100 0001 、 0100 0010 。对于储存字符串 AB ,我们可以 0100 0001 0100 0010 也可以 0100 0010 0100 0001 ,这个顺序就是所谓的字节序。
高/低位字节
比如字符串 AB ,左高右低(我们正常的阅读顺序), A 为高字节, B 为低字节
高/低地址
假设0x123456是按从高位到底位的顺序储存,内存中是这样存放的:
高地址 -> 低地址
12 -> 34 -> 56
大端字节序(网络字节序)
大端就是将高位字节放到内存的低地址端,低位字节放到高地址端。网络传输中(比如TCP/IP)低地址端(高位字节)放在流的开始,对于2个字节的字符串( AB ),传输顺序为: A (0-7bit)、 B (8-15bit)。
那么小端字节序自然和大端相反。
主机字节序
表示当年机器的字节序(也就是网络字节序是确定的,而主机字节序是依机器确定的), 一般 为小端字节序。
a和A(打包字符串,用NUL或者空格填充)
$string = pack('a6', 'china');
var_dump($string); //输出结果: string(6) "china",最后一个字节是不可见的NUL
echo ord($string[5]); //输出结果: 0(ASCII码中0对应的就是nul)
//A同理
$string = pack('A6', 'china');
var_dump($string); //输出结果: string(6) "china ",最后一个字节是空格
echo ord($string[5]); //输出结果: 32(ASCII码中32对应的就是空格)
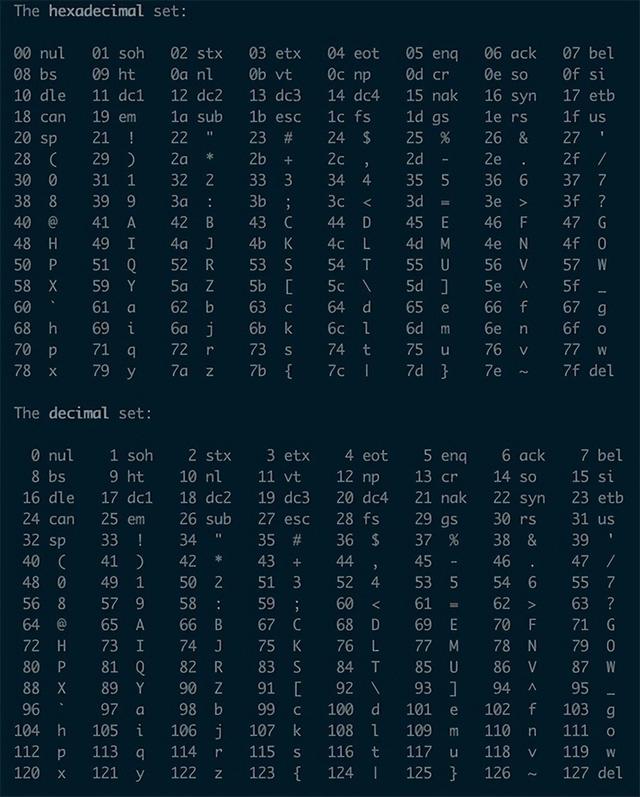
附赠ASCII表一张(linux/unix下可以使用 man ascii 查看)
h和H
$string = pack('H3', 281);
var_dump($string); //输出结果: string(2) "("
for($i=0;$i
h和H需要特殊说明一下,它们是将对应的参数看做十六进制字符然后打包。什么意思呢?比如上面的 281 ,打包前会将 281 转换为 0x281 ,因为十六进制的一位对应二进制的四位,上面的 0x281 只有1.5个字节,后面会默认补0变成 0x2810 ,0x28对应的十进制为40( ( ),0x10对应的十进制为16( dle 不可见字符),懂了吧?不懂的可以给我留言。。
c和C
$string = pack('c3', 67, 68, -1);
var_dump($string); //输出:string(3) "CD�"
for($i=0;$i
最后输出本能应该觉得是67 68 -1
ord获取的是字符的ASCII码( 范围0-255 ),这时 -1(0000 0001) 对应的字符将以补码的形式输出也就是 255(1111 1110 + 0000 0001 = 1111 1111)
整型相关
所有的整型类型使用方法完全一样,主要注意它们的位和字节序就可以了,下面以L作为例子展示
$string = pack('L', 123456789);
var_dump($string); //输出:string(4) "�["
for($i=0;$i
f和d
$string = pack('f', 12345.123);
var_dump($string);
//输出:string(4) "~�@F"
var_dump(unpack('f', $string)); //这里提前用到了unpack,后面会讲解
//输出:float(12345.123046875)
f和d是针对浮点数打包,至于为什么打包前是 12345.123 解包后是 12345.123046875 ,这个和浮点数的储存有关系,后面可以单开一个文章讲解一下IEEE标准
x、X、Z、@
$string = pack('x'); //打包一个nul字符串
echo ord($string); //输出: 0
关于 X(大写X) ,试了N次,没搞明白怎么用,有清楚的童鞋可以给我留言,多谢。
$string = pack('Z2', 'abc5'); //其实就是将从Z后面的数字位置开始,全部设置为nul
var_dump($string); //输出:string(2) "a"
for($i=0;$i
$string = pack('@4'); //我理解为填充N个nul
var_dump($string); //输出: string(4) ""
for($i=0;$i
unpack
array unpack ( string $format , string $data )
unpack的使用相当简单,就是讲pack打包的数据解包,打包的时候用的什么参数,就用什么参数解包,具体使用懒得说了,列几个小例子
$string = pack('L4', 1, 2, 3, 4);
var_dump(unpack('L4', $string));
//输出:
array(4) {
[1]=>
int(1)
[2]=>
int(2)
[3]=>
int(3)
[4]=>
int(4)
}
$string = pack('L4', 1, 2, 3, 4);
var_dump(unpack('Ll1/Ll2/Ll3/Ll4', $string)); //可以指定key,用/分割
//输出:
array(4) {
["l1"]=>
int(1)
["l2"]=>
int(2)
["l3"]=>
int(3)
["l4"]=>
int(4)
}
这两个函数到底有啥用途
- 数据通信(通过二进制格式与其它语言通信)
- 数据加密(如果不告诉第三方你的打包方式,对方解包的难度就相对很大)
- 节省空间(比如比较大的数字按字符串储存会浪费很多空间,打包成二进制格式才需要4位<32位数字>)
- 自己去想吧
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24