神奇的Python模块:pdfkit,将Python抓取的网址内容保存pdf文件
图/文:迷神
写 Python 爬虫写的多了,有时候想把网址页面内容,按照标题.pdf模式,直接保存为pdf电子书的形式。这样也非常方便备档阅读,特别是一些简洁的比如微信公众号的里面的文章,很简洁,很适合将网址内容保存成pdf文档。
于是,我就发现了神奇的Python模块:pdfkit,他可以将Python抓取的网址内容保存pdf文件形式,很优美的赶脚。

pdfkit安装,很简单,一行命令即可:
pip install pdfkit
pdfkit需要一个wkhtmltopdf的软件做支持,如图:

wkhtmltopdf软件下载
我是win10系统64,下载wkhtmltopdf第一个如图的就行,然后将安装目录下的 bin 添加到 环境变量 的path中,如果不设置环境变量,那就需要指定了这个文件目录。
import pdfkit
class pdf:
def make(self):
config = pdfkit. configuration (wkhtmltopdf=r"D:\wkhtmltopdf\bin\wkhtmltopdf.exe")
pdfkit.from_url("url网址", "1.pdf", configuration=config)
if __name__ == '__main__':
p = pdf()
p.make()
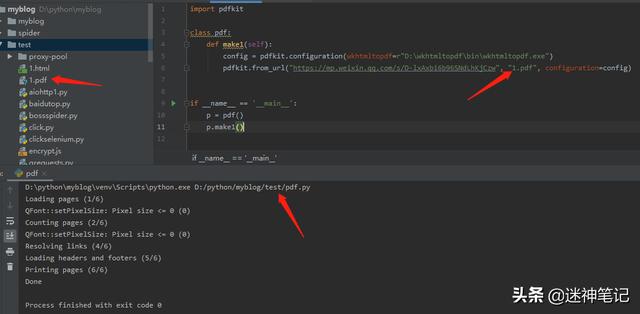
执行结果
代码执行完之后,就可以看到1.pdf文件了,我使用的 微信 的地址,微信简洁清爽,这个pdf生成,超过一页了,可以有多页进行完整存储还是不错的。
pdfkit模块的 源码 中,代码量不大,大家喜欢可以看看,接口文件:pdfkit/ api .py,主要包含以下方法也在里面。
从接口文档上看,pdfkit可以支持三种的方法,除了上面,我们说的传入url地址之外,还支持另外两种模式:
1、form_file:传入的参数为 html文件
def from_file( input , output_path, options=None, toc=None, cover=None,
css=None,configuration=None, cover_first=False)
2、form_string:传入的参数为 字符串
def from_string(input, output_path, options=None, toc=None, cover=None, css=None,
configuration=None, cover_first=False)
好了,就这么多啦,我是迷神,更多精彩,记得关注我哦,请多多转发,有问题也可以评论哦。
相关文章
- Linux怎么在命令行下提取PDF文件中的文本
- Lightly IDE 快捷键:Python 开发者必学的效率提升操作
- GitHub Codespaces 模板配置:快速初始化项目环境的技巧
- Python 类型注解进阶:mypy 静态类型检查与 IDE 集成
- Python 3.12 模式匹配增强:结构分解与多分支逻辑简化实战
- Lightly IDE 快捷键定制:Python 开发者专属效率提升方案
- Python 装饰器高级用法:类装饰器与元类结合实践
- Python 生成器表达式优化:内存占用与迭代效率平衡技巧
- Python 类型注解深度:Protocol 协议与泛型类型约束实践
- Python 3.12 新特性解析:模式匹配增强与性能优化实战
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24