网络爬虫的工作原理,以及解析获取到的html页面内容(NSoup)
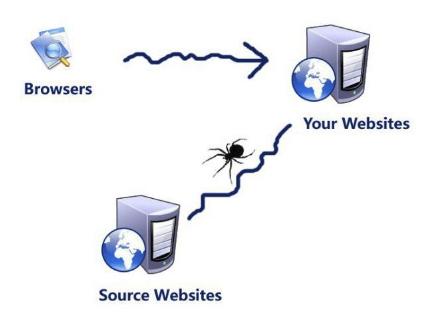
网络爬虫是一个自动提取网页的程序,它从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
那么在这个过程中我们怎么抽取新的URL地址呢?这时候就需要解析html内容了,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索,从中检索出需要的URL交给爬虫,让它继续工作,整个过程就一个蜘蛛不断建网,四通八达。
下面程序可以从页面中提取我们想要的东西,比如标题、正文,想要深入爬取的话,我们就需要解析其中有用的URL出来。
public string url = “”;
protected void Page_Load(object sender, EventArgs e)
{
url = Web. DLL . Utility . request Utility.GetString(“url”);
string op = Web.DLL.Utility.RequestUtility.GetString(“op”);
if (op == “getrealurl”)
{
Hashtable hash = new Hashtable();
string out_link = “”;
string html = GetHtml(url, Encoding .UTF8);
NSoup.Nodes.Document doc = NSoup.NSoupClient.Parse(html);
Elements elements = doc.GetElementsByClass(“mod_episodes_numbers”);
Elements elements_a = elements.Select(“a”);
foreach (var item in elements_a)
{
string text_str = item.Text();
string href _str = item.Attr(“href”).ToString();
out_link += “void (0)\” onclick=\”play(‘” + href_str + “‘)\”>” + text_str + ” “;
}
hash[“error”] = 0;
hash[“backurl”] = “” + url;
hash[“backhtml”] = out_link;
Response.Write(JsonMapper.ToJson(hash));
Response.End();
}
}
/// < summary >
/// 获取网页源代码
///
///
///
public string GetHtml(string url, encoding encoding)
{
HttpWebRequest request = null;
HttpWebResponse response = null;
StreamReader reader = null;
try
{
request = (HttpWebRequest)WebRequest.Create(url);
request.Timeout = 20000;
request.AllowAutoRedirect = false;
response = (HttpWebResponse)request.GetResponse();
if (response.StatusCode == HttpStatusCode.OK && response.ContentLength < 1024 * 1024)
{
if (response.ContentEncoding != null && response.ContentEncoding.Equals(“gzip”, StringComparison.InvariantCultureIgnoreCase))
reader = new StreamReader(new GZipStream(response.GetResponseStream(), CompressionMode.Decompress), encoding);
else
reader = new StreamReader(response.GetResponseStream(), encoding);
string html = reader.ReadToEnd();
return html;
}
}
catch
{
}
finally
{
if (response != null)
{
response. Close ();
response = null;
}
if (reader != null)
reader.Close();
if (request != null)
request = null;
}
return string.Empty;
}
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24