ElasticSearch大数据分布式弹性搜索引擎该如何使用
本篇文章为大家展示了ElasticSearch大数据分布式弹性搜索引擎该如何使用,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
1.背景
两年前有机会接触过elasticsearch,但是未做深入学习,只是工作中用到了。越来越发现es是个不错的好东西,所以花了点时间好好学习了下。在学习过程中也发现了一些问题,网上大多资料都很零散,大部分都是实验性的demo,很多问题并没有讲清楚也并没有系统的讲完整一整套方案,所以耐心的摸索和总结了一些东西分享出来。
毕竟当你用生产使用的标准来使用es时会有很多问题,这对你的学习提出来了新的标准。
比如,使用elasticsearch servicewrapper进行自启动的时候难道就没发现它的配置中有一个小bug导致load不了elasticsearch jar包中的class吗。
还有es不同版本之间的差异巨大,比如,1.0中的分布式routing在2.0中进行了巨大差异的修改。原本routing是跟着mapping一起配置的,到了2.0却跟着index动态走了。这个调整的本质目的是好的,让同一个index的不同type都有机会选择shard的片键。如果是跟着mapping走的话就只能限定于当前index的所有type。
es是个好东西,现在越来越多的分布式系统都需要用到它来解决问题。从ELK这种系统层的工具到电商平台的核心业务交易系统的设计都需要它来支撑实时大数据搜索分析。比如,商品中心的上千万的sku需要实时搜索,再到海量的在线订单实时查询都需要用到搜索。
在一些DevOps的工具中都需要es来提供强大的实时搜索功能。值得花点时间好好研究学习下。
作为电商架构师,所以没有什么理由不去学习和使用它来提高系统的整体服务水平。本篇文章将自己这段时间学习的经验总结出来分享给大家。
2.安装
首先你需要几台linux机器,你跑虚机也行。你可以在一台虚拟机上完成安装和配置,然后将当前虚拟机clone出多份修改下IP、HWaddr、UUID即用,这样方便你使用,而不需要再重复的安装配置。
1.我本地是三台Linux centos6.5,IP分别是,192.168.0.10、192.168.0.20、192.168.0.30。
(我们先在192.168.0.10上执行安装配置,然后一切就绪之后我们将这个节点clone出来修改配置,然后再配置集群参数,最后形成可以工作的以三个node组成的集群实例。)
2.由于ElasticSearch是java语言开发的,所以我们需要预先安装好java相关环境。我使用的是JDK8,直接使用yum安装即可,yum仓库有最新的源。
先查看你当前机器是否安装了java环境:
yum info installed |grep java*
如果已经存在java环境且这个环境不是你想要的,你可以卸载然后重新安装你想要的版本。(yum –y remove xxx)如果卸载不干净,你可以直接find 查找相关文件,然后直接物理删除。linux的系统都是基于文件的,只要能找到基本上都可以删除。
先看下有哪些版本:
yum search java
java-1.8.0-openjdk.x86_64 : OpenJDK Runtime Environment(找到这个源)
然后执行安装:
yum –y install java-1.8.0-openjdk.x86_64
安装好之后查看java 相关参数:
java –version
预备工作我们已经做好,接下来我们将执行ElasticSearch的环境安装和配置。
2.1.查找、下载rpm包、执行rpm包安装
你可以有几种方式安装。使用yum repository是最快最便捷的,但是一般这里面的版本应该是比较滞后的。所以我是直接到官网下载rpm包安装的。
elasticsearch官方下载地址:https://www.elastic.co/downloads/elasticsearch
找到你对应的系统类型文件,当然如果你是windows系统那就直接下载zip包使用就行了。这里我需要rpm文件。
你也可以安装本地yum 源,然后还是使用yum命令安装。
我是使用wget 工具直接下载RPM文件到本地的。(如果你的包有依赖建议还是yum方式安装。)
(如果你的wget命令不起作用,记得先安装:yum -y install wget)
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.4.0/elasticsearch-2.4.0.rpm
然后等待下载完成。
这里有个东西需要提醒下,就是你是否要安装最新版本的elasticsearch,个人建议还是安装稍微低一个版本的,我本地安装的是2.3.4的版本。为什么要这样强调尼,因为当你安装了很高的版本之后有一个很大的问题就是中文分词器能否支持到这个版本。从2.3.5之后就直接到2.4.0的版本了,我当时安装的是2.3.5的版本后来发现一个问题就是ik中文分词器我得git clone下来编译后才能有输出部署文件。所以建议大家安装2.3.4的版本,2.3.4的版本中文分词器就可以直接在linux服务器里下载部署,很方便。
执行安装:
rpm -iv elasticsearch-2.3.4.rpm
然后等待安装完成。
不出什么意外,安装就应该完成了。我们进行下基本的安装信息查看,是否安装之后缺少什么文件。因为有些包里面会缺少一些config配置。如果缺少我们还得补充完整。
为了方便查看安装涉及到的文件,你可以导航到根目录下 find。
cd /
find . –name elasticsearch
./var/lib/elasticsearch
./var/log/elasticsearch
./var/run/elasticsearch
./etc/rc.d/init.d/elasticsearch
./etc/sysconfig/elasticsearch
./etc/elasticsearch
./usr/share/elasticsearch
./usr/share/elasticsearch/bin/elasticsearch
基本上差不多了,你还得看下是否缺少config,因为我安装的时候是缺少的。
cd /usr/share/elasticsearch/
ll
drwxr-xr-x. 2 root root 4096 9月 4 01:10 bin
drwxr-xr-x. 2 root root 4096 9月 4 01:10 lib
-rw-r--r--. 1 root root 11358 6月 30 19:22 LICENSE.txt
drwxr-xr-x. 5 root root 4096 9月 4 01:10 modules
-rw-r--r--. 1 root root 150 6月 30 19:22 NOTICE.txt
drwxr-xr-x. 2 elasticsearch elasticsearch 4096 6月 30 19:32 plugins
-rw-r--r--. 1 root root 8700 6月 30 19:22 README.textile
大概看下你应该也是缺少config文件夹的。我们还得把这个文件夹建好,同时还需要一个elasticsearch.yml配置文件。要不然启动的时候肯定是报错的。
mkdir config
cd config
vim elasticsearch.yml
找一下elasticsearch.yml配置贴上去,或者你用文件的方式传送也行。这些配置都是基本的,回头还需要根据情况调整配置的。有些配置在配置文件中是没有的,还需要到官方上去查找的。所以这里无所谓配置文件的全或者不全。关于配置项网上有很多资料,所以这个无所谓的。
保存下elasticsearch.yml文件。
你还需要一个logging.yml日志配置文件。es作为服务器后台运行的服务是肯定需要日志文件的。这部分日志会被你的日志平台收集和监控,用来做为运维健康检查。logging.yml本质上是一个log4j的配置文件,这个应该大家都比较熟悉了。跟elasticsearch.yml类似,要么复制粘贴要么文件传送。
日志的输出在logs目录下,这个目录会被自动创建。但是我还是喜欢创建好,不喜欢有不确定因素,也许它就不会自动创建。
mkdir logs
最后需要设置下刚才我们添加的文件的执行权限。要不然你的文件名字应该是白色的,是不允许被执行。
cd ..
chmod –R u+x config/
现在基本上安装算是完成了,试着cd到文件的启动目录下启动es,来检查下是否能正常启动。
不出意外你会收到一个 “java.lang.RuntimeException: don't run elasticsearch as root”异常。这说明我们完成了第一步安装过程,下节我们来看有关启动账户的问题。
2.2.配置elasticsearch专属账户和组
默认情况下es是不允许root账户启动的,这是为了安全起见。es默认内嵌了groovy脚本引擎的功能,还有很多plugin脚本引擎插件,确实不×××全。es刚出来的时候还有groovy漏洞,所以建议在产线的es instance 关掉这个脚本功能。虽然默认不是开启的,安全起见还是检查一下你的配置。
所以我们需要为es配置独立的账户和组。在创建es专用账户之前先查看下系统里面是否已经有了es专用账户。因为在我们前面rpm安装的时候会自动安装elasticsearch组和用户。先查看下,如果你的安装没有带上专用组和用户然后你在创建。这样以免你自己增加的和系统创建的搞混淆。
查看下组:
cat /etc/group
查看下用户:
cat /etc/passwd
基本上都创建好了。499的group在passwd中也创建了对应的elasticsearch账号。
如果你系统里没有自动创建对应的组和账号,你就动手自己创建,如下:
创建组:
groupadd elasticsearch_group
创建用户:
useradd elasticsearch_user -g elasticsearch_group -s /sbin/nologin
注意:此账户是不具有登录权限的。它的shell是在/sbin/nologin。
为了演示,在我的电脑上有两组elasticsearch专用账户,我将删除“_group”和“_user”结尾的账号,以rpm自动安装的为es的启动账号(elasticsearch)。
2.3.设置elasticsearch文件所有者
接下来我们需要做的就是关联es文件和elasticsearch账号,将es相关的文件设置成elasticsearch用户为所有者,这样elasticsearch用户就可以没有任何权限限制的使用es所有文件。
导航到elasticsearch上级目录:
cd /usr/share
ll
chown -R elasticsearch:elasticsearch elasticsearch/
此时,你的elasticsearch文件的owner是elasticsearch。
2.4.切换到elasticsearch专属账户测试能否成功启动
为了测试启动es实例,我们需要暂时的将elasticsearch的用户切换到/bin/bash。这样我们就可以su elasticsearch,然后启动es实例。
su elasticsearch
cd /usr/share/elasticsearch/bin
./elasticsearch
启动完成,此时应该没发生任何异常。看下系统端口是否启动成长。
netstat –tnl
继续查看下HTTP服务是否启动正常。
curl –get http://192.168.0.103:9200/_cat
由于此时我们并没有安装任何辅助管理工具,如,plugin/head。所以用内置的_cat rest endpoit还是挺方便的。
curl -get http://192.168.0.103:9200/_cat/nodes
192.168.0.103 192.168.0.103 4 64 0.00 d * node-1
可以看见,目前只有一个节点在工作,192.168.0.103,且它是一个data node。
(备注:为了节省时间,我暂时先使用一台103的干净环境作为安装和环境搭建演示,当搭建集群的时候我会clone出来和修改IP。)
2.5.安装自启动elasticsearch servicewrapper包
es的系统自启动有一个开源的wrapper包可以使用。如果你不使用这个wrapper也可以自己去写shell脚本,但是里面的很多参数需要你搞的非常清楚才行,在加上有些关键参数需要设置。所以还是建议在elasticsearchwrapper包的基础上进行修改效率会高点,而且你还能在elasticsearch shell中看见一些es深层次的配置和原理。
(备注:如果你是.neter,你可以将servicewrapper理解成是开源.net topshelf。本质就是将程序包装成具有系统服务功能,你可以安装、卸载,也可以直接启动、停止,或者干脆直接前台运行。)
2.5.1.下载elasticsearch servicewrapper 包
elasticsearchwrapper github首页,https://github.com/elastic/elasticsearch-servicewrapper
复制 git repository 地址到剪贴板,然后直接clone到本地。
git clone https://github.com/elastic/elasticsearch-servicewrapper.git
(你需要在当前linux机器上安装git客户端:yum –y install git,我安装的是默认1.7的版本。)
然后等待clone完成。
查看下clone下来的本地仓库文件情况。进入elasticsearchwrapper,查看当前git 分支。
cd /root/elasticsearch-servicewrapper
git branch
*master
ll
一切都很正常,说明我们clone下来没问题,包括分支也是很清晰的。service文件就是我们要安装的安装文件。
我们需要将service文件copy到elasticsearch/bin目录下。
cp -R service/ /usr/share/elasticsearch/bin/
cd /usr/share/elasticsearch/bin/
service里的安装文件需要在elasticsearch/bin目录下工作。
cd service/
ll
./elasticsearch
参考github上elasticsearchwrapper使用说明。elasticsearch servicewrapper的功能还是蛮多的,status、dump都是很好的检查和调试工具。
在安装之前,我们需要暂时在前台运行es实例,这样可以查看一些log是否有异常情况。Parameter的各个参数写的很清楚,我们这里使用console控制台输出启动es实例。
./elasticsearch console
2.5.2 elasticsearch servicewrapper开源包的配置小bug
此时你应该会收到一个Error的提示:
WrapperSimpleApp Error: Unable to locate the class org.elasticsearch.bootstrap.ElasticsearchF : java.lang.ClassNotFoundException: org.elasticsearch.bootstrap.ElasticsearchF
第一次看到这个我有点蒙,这个ElasticsearchF是个什么对象。命名有点特殊,再进一步查看Exception的信息,其实是一个ClassNotFoundException异常。说明找不到这个ElasticSearchF类。
两种可能性,第一就是java elasticsearch相关包的问题,确实缺少这个类。但是这个可能性很小,因为我们之前直接运行elasticsearch是成功的。我当时用jd-gui翻了下es的包,确实没有这个类。
第二就是这里的配置错误,应该就个手误,确实没有ElasticsearchF这个类。
我们查看下service/elasticsearch.conf配置文件里是不是有这个‘elasticsearchF’字符串。(wrapper包是使用当前目录下的elasticsearch.conf作为配置文件使用的)
grep –i elasticsearchf elasticsearch.conf
确实有这个字符串,我们进行编辑保存,去掉最后的‘F’。
然后我们在进行启动尝试。
./elasticsearch console
我不知道你是不是会和我的情况一样,提示相关命令都是不规范的。
这个运行链路基本上经过三个路径,第一个就是service/elasticsearch shell启动脚本,然后获取命令分析命令再启动exec下的相关java servicewrapper程序。
这个java servicewrapper程序,版本是3.5.14。根据上述思路,通过查看elasticsearch shell程序,它在接收到外部的命令之后会启动exec下的java servicewrapper程序。我想试着编辑了下elasticsearch shell文件,输出一些信息出来,查看下是不是获取相关路径或者参数之类的导致错误。(遇到问题不怕,至少我们要一路跟下去,看下究竟是怎么回事。)
vim ./elasticsearch
esc
:/console
找下console在哪里,然后加上调试文本信息,输出到界面上。
再运行,查看命令参数是否有问题。
查看了下,输出的参数基本都没有问题。一时无解。好奇心作怪,本想再进一步看下exec/elasticsearch-linux-x86-64.so文件的,后来发现打开根本就看不懂。所以就另寻其他方法,我找了windows版本servicewrapper,发现windows的elasticsearchservicewrapper是没有32位的servicewrapper的。我试着运行起来基本上也是报相同的错误,但是windows的wrapper的error信息比较多点,提示出错的原因在哪里。
我想修改下日志的输出级别,看能否输出一些可以用的信息。编辑service/elasticsearch.conf wrapper包专用配置。
# Log Level for console output. (See docs for log levels)
wrapper.console.loglevel=TRACE
# Log Level for console output. (See docs for log levels)
wrapper.console.loglevel=TRACE
我们将日志输出级别设置成trace,有两处需要设置,我们再看输出信息。
是输出了一些有用的信息,可以查看log文件详情。
WrapperManager Debug: Received a packet LOGFILE : /usr/share/elasticsearch/logs/service.log
但是有关于error的信息还是只有一条。
这里就告一段落。我们的目的是为了使用console来运行,想查看下一些运行日志,但是跑不起来也无所谓,我们继续执行安装操作。
(哪位博友如果知道问题在哪里的可以分享出来,我觉得这个问题不是一个偶发性问题,应该都会遇到。我先抛出问题,至少可以服务将来的使用者。这里先谢谢了。)
其实,如果你不使用elasticsearch servicewrapper来包装而是自己去下载java serivcewrapper来包装elasticsearch也是可以的,实现起来也很方便。
我们回到主题,既然我们无法console运行,也看不了一些wrapper console执行时的情况,那我们就只能进行安装了。
2.5.3 servicewrapper安装 (elasticsearch init.d 启动文件设置user、openfile、configpath)
按照elasticsearch servicewrapper parameter参数指示,我们执行安装。
./elasticsearch install
Installing the Elasticsearch daemon..
守护进程安装完成。我们还是前去系统目录下查看是不是安装成功(技术人员始终保持一个严谨的心态是有必要的。)前往/etc/init.d/目录下查看。
ll /etc/init.d/
-rwxrwxr--. 1 root root 4496 10月 4 01:43 elasticsearch
我这里设置过chmod u+x ./elasticsearch。别忘记设置文件的执行权限,这在我们【2.1节】里将结果,这里就不重复了。
我们开始编辑elasticsearch启动文件。
主要就是这段,填写好配置的es的专用账户(elasticsearch【2.2.节】),还有相应的文件路径。这里先忽略MAX_OPEN_FILES、MAX_MAP_COUNT两个配置项,在后面【3.3.节】配置部分会讲解到。
2.5.4 chkconfig -add 加入linux启动服务列表
将其添加到系统服务中,以便被系统自动启动。
chkconfig --add elasticsearch
chkconfig –list
已经添加好系统自启动服务列表中。
service elasticsearch start
启动es实例,等待端口启动完成,稍等片刻查看端口情况。
netstat –tnl
9300端口比9200端口先启动,因为9300端口是 cluster内部管理端口。9200是rest endpoint 服务端口。当然,这个时间延长不会很长。
端口都启动成功之后,我们查看下能否正常访问es实例。
curl -get http://192.168.0.103:9200/
{
"name" : "node-1",
"cluster_name" : "orderSearch_cluster",
"version" : {
"number" : "2.3.4",
"build_hash" : "e455fd0c13dceca8dbbdbb1665d068ae55dabe3f",
"build_timestamp" : "2016-06-30T11:24:31Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
我们还是使用_cat rest endpoint来查看。
curl -get http://192.168.0.103:9200/_cat/nodes
192.168.0.103 192.168.0.103 4 61 0.00 d * node-1
如果你可以在本机访问,但是在外部浏览器中无法访问,很可能是防火墙的设置问题,你可以去设置下防火墙。
vim /etc/sysconfig/iptables
重启网络服务,以便加载防火墙设置项。
service network restart
然后再尝试看能否外部访问,如果不行你就telnet端口下。
因为访问不了还有一个原因是和elasticsearch.yml一个配置项有关系。见【3.1.1节】。
重启机器,查看es实例是否会自动启动。
shutdown –r now
稍等片刻,然后尝试连接机器。
如果没出什么意外,都应该正常的,端口也启动成功了。说明我们完成了es实例自启动功能,它现在作为linux系统服务被自动管理。
安装成服务之后,elasticsearch servicewrapper和我们就没有太多关系了。因为它的parameter都是围绕者我们基于servicewrapper来使用的。
2.6.安装_plugin/head管理插件(辅助管理)
为了很好的管理集群,我们需要相应的工具,head是比较流行和通用的,而且是免费的。当然还有很多好用的其他工具,如,Bigdesk、Marvel(商用收费)。plugin的安装都大同小异,我们这里就使用通用的head工具。
先看下,head给我们带来的清晰的集群节点管理视图。
这是有三个节点的es集群实例。它是一个二维矩阵排列,最上面横向是索引,最左边是节点,交叉的地方是索引的分片信息和分片比例。
安装head插件还是比较方便的,你也可以直接copy文件的方式使用。在elasticsearch的home目录下有一个plugins目录,它是所有插件的目录,所有的插件都会在这个文件夹查找和加载。
我们看下安装head插件方法。在elasticsearch/bin 目录下有一个plugin可执行文件,它是专门用来安装插件用的程序。
./plugin -install mobz/elasticsearch-head
插件的查找路径有几个elasticsearch官网是一个,github是一个。这里会先尝试在github上查找,稍等片刻,等待安装完成。我们尝试访问head插件地址rest地址/_plugin/head。
看到这个界面基本安装成功了,node-1默认是master节点。
2.7.安装chrom中的elasticsearch客户端插件
chrom中有很多可以使用的elasticsearch客户端插件,便于开发和维护,建议直接使用chrom中的插件。只要搜索下elasticsearch关键字就会出来很多。
有两个比较常用,也比较好用,EalsticSearch Toolbox、Sense(自动提示dsl编辑工具)。chrom插件都是那么的酷,使用起来都很赏心悦目。
elasticsearch toolbox 可以很方便的查询和导出数据。
sense可以让你编辑elasticsearch dsl 特定语言会有启动提示帮助,这样编写起复杂的dsl效率会高而且不易出错。其他的工具我也没用过,感觉都可以尝试用用看。
(备注:如果你无法访问chrom商店中心就需要特殊处理下,这里就不解释了。)
2.8.使用elasticsearch自带的_cat工具
在一些特殊的情况下你可能无法直接使用plugin来帮你管理或者查看集群情况。此时你可以直接使用elasticsearch自带的rest _cat查看集群情况,比如,你可能发现_plugin/head有一些节点没有上来,但是你又不确定发生了什么情况,你就可以使用/_cat/nodes来查看所有node的情况。有时候确实有的节点没有启动起来,但是大多数情况下都是各自为政(脑裂),你可能需要让他们重新选举或者加快的选举过程。
http://192.168.0.20:9200/_cat/nodes?v (查看nodes情况)
_cat rest端点带有一个v的参数,这个参数是帮助你阅读的参数。_search rest端点带有pretty参数,这个参数是帮助查询数据阅读的。每一个端点基本上都有各自的辅助阅读参数。
http://192.168.0.20:9200/_cat/shards?v(查看shards情况)
http://192.168.0.20:9200/_cat/ (查看所有可以cat的功能)
你可以查看系统 aliases别名、segments片段(看下每个片段的提交版本一致性)、indices索引集合等等。
2.9.clone 虚机(修改IP、HWaddr、UUID配置,最后修改下系统时间)
当我们完成了对一台机器的安装之后,接下来就需要搭建分布式系统。分布式系统就需要多节点机器,按照es分布式集群搭建最佳实践,你至少需要三个节点。所以我们将已经安装完成的这个机器clone出来两台,一共三台组成可以工作的三个节点的分布式系统。
首先clone当前安装完成的机器,192.168.0.103,clone好之后启动起来修改几个配置即可。(因为你是clone出来的,所以配置已经重复,比如,网卡地址、IP地址)
编辑网卡配置文件:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth4
HWADDR=00:0C:29:CF:48:23
TYPE=Ethernet
UUID=b848e750-d491-4c9d-b2ca-c853f21bf40b
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
BROADCAST=192.168.233.255
IPADDR=192.168.0.103
NETMASK=255.255.255.0
GATEWAY=192.168.0.1
DEVICE 是网卡标示,根据你本地的网卡标识修改成对应的即可,可以通过ifconfig查看。HWADDR网卡地址,随意修改下,保证在你的网段内不重复即可。UUID也是和HWADDR一样修改。
IP地址修改成你自己觉得合适的IP,最好参考你当前物理机器的相关配置。GATEWAY网关地址要参考你物理机器的网关地址,如果你的虚拟机使用的是桥接模式的网络连接,这里就需要设置,要不然网络就连接不上。
重启网络服务:
service network restart
稍等片刻,ssh重新连接,然后ifconfig看下网络相关参数是否正确,最后再ping一下外部网址和你当前物理机器的IP,保证网络都是通畅的。
最后我们需要修改下linux的系统时间,这是为了防止服务器时间不一致,导致很多细微的问题,比如,es集群master选举的时间戳问题、log4j输出的日志的记录问题等等。在分布式系统中,时钟非常重要。
date -s '20161008 20:47:00'
时区的话如果你需要也可以设置,这里暂时不需要。
根据你自己的需要,你clone几台机器。按照默认的方式我们大概约定为,192.168.0.10、192.168.0.20、192.168.0.30,这三台机器将组成一个es分布式集群。
3.配置
集群的各个节点我们已经准备好了,我们接下来准备配置集群,让这三个节点可以连接在一起。这里涉及的配置比较简单,只是完成集群的一个基本常用功能,如有特殊的需求可以自行查看elasticsearch官网或者百度,这方面的资料已经很丰富了。
这里的一些配置我们其实已经受益于elasticsearch servicewrapper简化了很多。
从这里开始,我们将对三台机器进行配置,192.168.160.10、192.168.160.20、192.168.160.30。
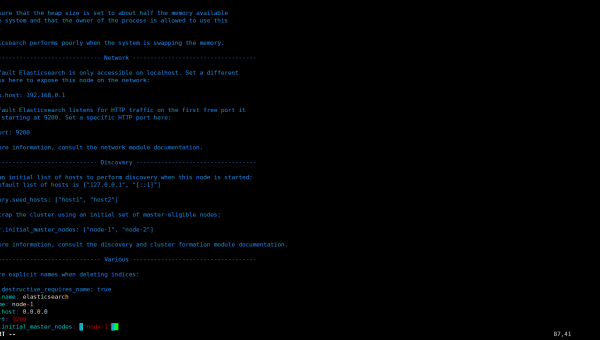
3.1.elasticsearch.yml配置
在elasticsearch的config目录下都是配置文件。导航到 cd /usr/share/elasticsearch/config目录。
3.1.1.IP访问限制、默认端口修改9200
这里有两个需要提醒下,第一个就是IP访问限制,第二个就是es实例的默认端口号9200。IP访问限制可以限定具体的IP访问服务器,这有一定的安全过滤作用。
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
如果设置成0.0.0.0则是不限制任何IP访问。一般在生产的服务器可能会限定几台IP,通常用于管理使用。
默认的端口9200在一般情况下也有点风险,可以将默认的端口修改成另外一个,这还有一个原因就是怕开发人员误操作,连接上集群。当然,如果你的公司网络隔离做的很好也无所谓。
#
# Set a custom port for HTTP:
#
http.port: 9200
transport.tcp.port: 9300
这里的9300是集群内部通讯使用的端口,这个也可以修改掉。因为连接集群的方式有两种,通过扮演集群node也是可以进入集群的,所以还是安全起见,修改掉默认的端口。
(备注:记得修改三个节点的相同配置,要不然节点之间无法建立连接工作,也会报错。)
3.1.2.集群发现IP列表、node、cluster名称
紧接着修改集群节点IP地址,这样可以让集群在规定的几个节点之间工作。elasticsearch,默认是使用自动发现IP机制。就是在当前网段内,只要能被自动感知到的IP就能自动加入到集群中。这有好处也有坏处。好处就是自动化了,当你的es集群需要云化的时候就会非常方便。但是也会带来一些不稳定的情况,如,master的选举问题、数据复制问题。
导致master选举的因素之一就是集群有节点进入。当数据复制发生的时候也会影响集群,因为要做数据平衡复制和冗余。这里面可以独立master集群,剔除master集群的数据节点能力。
固定列表的IP发现有两种配置方式,一种是互相依赖发现,一种是全量发现。各有优势吧,我是使用的依赖发现来做的。这有个很重要的参考标准,就是你的集群扩展速度有多快。因为这有个问题就是,当全量发现的时候,如果是初始化集群会有很大的问题,就是master全局会很长,然后节点之间的启动速度各不一样。所以我采用了靠谱点的依赖发现。
你需要在192.168.0.20的elasticsearch中配置成:
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: [ "192.168.0.10:9300" ]
让他去发现10的机器,以此内推,完成剩下的30的配置。
(备注:网上有很多针对不同场景的发现配置,大家可以就此抛砖引玉,对这个主题感兴趣的可以百度很多资料的。)
然后你需要配置下集群名称,就是你当前节点所在集群的名称,这有助于你规划你的集群。只有集群名称一样才能组成一个逻辑集群。
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: orderSearch_cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-2
以此类推,完成另外两个节点的配置。cluster.name的名称必须保持一样。然后分别设置node.name。
3.1.3.master node 启动切换
这里有一个小小的经验分享下,就是我在使用集群的时候,因为我是虚拟化出来的机器所以经常会关闭和重启集群。有时候发现集群master宣酒会有一个问题就是,如果你的集群关闭的方式不对,会直接影响下个master选举的逻辑。
我查了下选举的大概逻辑,它会根据分片的数据的前后新鲜程度来作为选举的一个重要逻辑。(日志、数据、时间都会作为集群master全局的重要指标)
因为考虑到数据一致性问题,当然是用最新的数据节点作为master,然后进行新数据的复制和刷新其他node。
如果你发现有一个节点迟迟进不了集群,可以尝试重启下es服务,让集群master重新全局。
3.2.linux 打开最大文件数设置(用作index时候的系统阀值)
在linux系统中,要想使用最大化的系统资源需要向操作系统去申请。由于elasticsearch需要在index的时候用到大量的文件句柄资源,在原来linux默认的资源下可能会不够用。所以这里就需要我们在使用的时候事先设置好。
这个配置在《ElasticSearch 可扩展的开源弹性搜索解决方案》一书中作为重点配置介绍,可想而知还是有不少人踩到过的坑。
这个配置在elasticsearch service wrapper中帮我们配置好了。
vim /etc/init.d/elasticsearch
这个配置会被启动的时候设置到es实例中去。
这个时候试着重启三台机器的es实例,看能不能在_plugin/head中查看到三台机器的集群状态。(记得访问安装了head插件的那台机器,我这里是在10机器上安装的)
红色的就是你设置的node.name节点名称,他们在一个集群里工作。
3.3.安装中文分词器ik(注意对应版本问题)
此时集群应该可以工作了,我们还需要配置中文分词器,毕竟我们使用的中文,elasticsearch的自带的分词器对中文分词支持的不太适合本土。
我是使用的ik分词器,在github上的地址:https://github.com/medcl/elasticsearch-analysis-ik
先别急的clone,我们先来看下ik分词器所支持的elasticsearch对应的版本。
我们使用的elasticsearch版本为2.3.4。所以我们要找对应的ik版本,要不然启动的时候就直接报加载不了对应版本的ik插件。切换到release版本列表,找到对应的版本然后下载下来。
你可以直接下载到Linux机器上,也可以下载到你的宿主机器上然后复制到虚拟机上。如果你的elasticsearch版本是最新的,你可能就需要下载ik源码下来编译之后再部署。
当然你可以使用git+maven的方式安装,详细的安装步骤可以参见:https://github.com/medcl/elasticsearch-analysis-ik
这也比较简单,我这里就不重复了。安装好之后重启es实例。
3.4.elasticsearch集群规划(master尽量不要作为data节点,独立master为commander)
可以这样规划一个集群。master可以两台,这两个节点都是作为commander统筹集群层面的事务,取消这两台的data权利。然后在规划出三个节点的data集群,取消这三个节点的master权利。让他们安心的做好数据存储和检索服务。这是最小的粒度集群结构,可以基于这个结构进行扩展。
这样做有一个好处,就是职责分明,可以最大限度的防止master节点有事data节点,导致不稳定因素发生。比如,data节点的数据复制,数据平衡,路由等等,直接影响master的稳定性。进而可能会发生脑裂问题。
4.开发
我们进入最后一个环节,所有的东西都准备好了,我们是不是应该操作操作这个强大的搜索引擎了。come on。
4.1.接入集群方式
说到集群,就会有相应的问题随之而来,高可用、高并发、大数据、横向扩展等等。那么elasticsearh的集群大概是个什么原理。
首先client的在接入集群的时候为了保证高可用不是采用 vip漂移实现高可用,类似keepalived 这种。elasticserach在客户端连接的时候使用配置多个IP的方式来首先客户端sdk的负载。这已经是分布式系统常见的做法了。只有类似DB、cache这样中心化的集群需要使用,以为是它们的使用特点决定了。(数据一致性)
elasticsearch的所有节点都可以处理请求,节点越多并发QPS越高,相应的TPS会下降,但是下降的性能不是根据节点的正比例来的。(它使用quorum(法定人数)算法,保证可用性。)所以节点的复制不是我们想当然的那样。
连接es集群的方式有两种,性能高点的就是直接将client扮演成cluster node进去集群,同时取消自己的data权利。这通常都是用来做二次开发用的,你可以github clone下来源码添加自己的场景然后进入集群,可能你会干预选举,也可能会干预sharding,也可能会干预集群平衡。
elasticsearch 使用自己定义的一套DSL语言,使用restful方式使用,根据不同的rest end point来使用。比如,_search、_cat、_query等等。这些都是指点的rest端点。然后你可以post dsl到elasticsearch服务器处理。
elasticsearch search dsl:https://www.elastic.co/guide/en/elasticsearch/reference/current/search.html
elasticsearch dsl api:http://elasticsearch-dsl.readthedocs.io/en/latest/
例:
POST _search
{
"query": {
"bool" : {
"must" : {
"query_string" : {
"query" : "query some test"
}
},
"filter" : {
"term" : { "user" : "plen" }
}
}
}
}
可读性很强,在通过chrome插件Sense辅助编写,会比较方便。
但是一般都不会这么做,一般都是使用sdk连接集群。直接使用dsl的大多是在测试数据的时候或者在调试的时候。看sdk输出的dsl是否正确。就跟调试SQL差不多。
4.1.1.net nest使用(使用pool连接es集群)
.NET程序有开源包nest,直接在Nuget上搜索安装即可。
官网地址:https://www.elastic.co/guide/en/elasticsearch/client/net-api/1.x/nest-connecting.html
使用pool高可用的方式连接集群。
var node1 = new Uri("http://192.168.0.10:9200");
var node2 = new Uri("http://192.168.0.20:9200");
var node3 = new Uri("http://192.168.0.30:9200");
var connectionPool = new SniffingConnectionPool(new[] { node1, node2, node3 });
var settings = new ConnectionSettings(connectionPool);
var client = new ElasticClient(settings);
此时使用client对象就是软负载的,它会根据一定的策略来均衡的连接后台三个node。(可能是平均的、可能是权重的,具体没研究)
4.1.2.java jest使用
java 的话我是使用jest。我们创建一个maven项目,然后添加jest 相应的jar包maven引用。
io.searchboxjest2.0.3org.elasticsearchelasticsearch2.3.5
JestClientFactoryfactory=newJestClientFactory();Listnodes=newLinkedList();nodes.add("http://192.168.0.10:9200");nodes.add("http://192.168.0.20:9200");nodes.add("http://192.168.0.30:9200");HttpClientConfigconfig=newHttpClientConfig.Builder(nodes).multiThreaded(true).build();factory.setHttpClientConfig(config);JestHttpClientclient=(JestHttpClient)factory.getObject();SearchSourceBuildersearchSourceBuilder=newSearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.queryStringQuery("中华人名共和国"));searchSourceBuilder.field("name");Searchsearch=newSearch.Builder(searchSourceBuilder.toString()).build();JestResultrs=client.execute(search);System.out.println(rs.getJsonString());
{
"took": 71,
"timed_out": false,
"_shards": {
"total": 45,
"successful": 45,
"failed": 0
},
"hits": {
"total": 6,
"max_score": 0.6614378,
"hits": [
{
"_index": "posts",
"_type": "post",
"_id": "1",
"_score": 0.6614378,
"fields": {
"name": [
"王清培"
]
}
},
{
"_index": "posts",
"_type": "post",
"_id": "5",
"_score": 0.57875806,
"fields": {
"name": [
"王清培"
]
}
},
{
"_index": "posts",
"_type": "post",
"_id": "2",
"_score": 0.57875806,
"fields": {
"name": [
"王清培"
]
}
},
{
"_index": "posts",
"_type": "post",
"_id": "AVaKENIckgl39nrAi9V5",
"_score": 0.57875806,
"fields": {
"name": [
"王清培"
]
}
},
{
"_index": "class",
"_type": "student",
"_id": "1",
"_score": 0.17759356
},
{
"_index": "posts",
"_type": "post",
"_id": "3",
"_score": 0.17759356,
"fields": {
"name": [
"王清培"
]
}
}
]
}
}
返回的数据横跨多个索引。你可以通过不断的debug来查看链接IP是不是会启动切换,是不是会起到可用性的作用。
4.2.index开发
索引开发一般步骤比较简单,首先建立对应的mapping映射,配置好各个type中的field的特性。
4.2.1.mapping 配置
mapping是es实例用来在index的时候,作为各个字段的操作依据。比如,username,这个字段是否要索引、是否要存储、长度大小等等。虽然elasticsearch可以动态的处理这些,但是出于管理和运维的目的还是建议建立对应的索引映射,这个映射可以保存在文件里,以便将来重建索引用。
POST /demoindex
{
"mappings": {
"demotype": {
"properties": {
"contents": {
"type": "string",
"index": "analyzed"
},
"name": {
"store": true,
"type": "string",
"index": "analyzed"
},
"id": {
"store": true,
"type": "long"
},
"userId": {
"store": true,
"type": "long"
}
}
}
}
}
这是一个最简单的mapping,定义了索引名称为demoindex,类型为demotype的mapping。各个字段分别是一个json对象,里面有类型有索引是否需要。
这个在sense里编辑,然后直接post提交。
{
"acknowledged": true
}
通过查看创建好的索引信息确认是否是你提交的mapping设置。
4.2.2.mapping template配置
每次都通过手动的创建类似的mapping始终是个低效率的事情,elasticserach支持建立mapping模板,然后让模板自动匹配使用哪个mapping定义。
PUT log_template
{
"order": 10,
"template": "log_*",
"settings": {
"index": {
"number_of_replicas": "2",
"number_of_shards": "5"
}
},
"mappings": {
"_default_": {
"_source_": {
"enable": false
}
}
}
}
创建一个log类型的索引mapping。我们设置了两个基本的属性, "number_of_replicas": "2" 复制分数, "number_of_shards": "5" 分片个数。mappings里面设置了source字段默认不开启。
当我们提交所有以“log_xxx”名字格式的索引时将自动命中这个mapping模板。
可以通过_template rest端点查看已经存在的mapping模板,或者通过head插件的右上角的”信息”里面的”模板”菜单查看。
{"mq_template":{"order":10,"template":"mq*","settings":{"index":{"number_of_shards":"5","number_of_replicas":"2"}},"mappings":{"_default_":{"_source_":{"enable":false}}},"aliases":{}},"log_template":{"order":10,"template":"log_*","settings":{"index":{"number_of_shards":"5","number_of_replicas":"2"}},"mappings":{"_default_":{"_source_":{"enable":false}}},"aliases":{}},"error_template":{"order":10,"template":"error_*","settings":{"index":{"number_of_shards":"5","number_of_replicas":"2"}},"mappings":{"_default_":{"_source_":{"enable":false}}},"aliases":{}}}
这通常用于一些业务不想关的存储中,比如日志、消息、重大错误预警等等都可以设置,只要这些重复的mapping是有规律的。
4.2.3.index routing索引路由配置
在es对数据进行分片的时候是采用hash取余的方式进行的,所以你可以传递一个固定的key,那么这个key将作为你固定的路由规则。在创建mappings的时候可以设置这个_routing参数。这在1.0的版本中是这样的设置的,也就是说你当前type下的所有document都是只能用着这个路由key进行。但是在es2.0之后routing跟着index元数据走,这样可以控制单个index的路由规则,在提交index的时候可以单独制定_routing参数,而不是直接设置mappings上。
在2.0之后已经不再支持mappings配置_routing参数了。
https://www.elastic.co/guide/en/elasticsearch/reference/current/breaking_20_mapping_changes.html#migration-meta-fields
在1.0里,比如,你可以将userid作为routing key,这样就可以将当前用户的所有数据都在一个分片上,当查询的时候就会加快查询速度。
{
"mappings": {
"post": {
"_routing": {
"required": true,
"path":"userid"
},
"properties": {
"contents": {
"type": "string"
},
"name": {
"store": true,
"type": "string"
},
"id": {
"store": true,
"type": "long"
},
"userId": {
"store": true,
"type": "long"
}
}
}
}
}
这个_routing是设置在mapping上的,作用于所有type。会使用userid作为sharding的key。但是在2.0里,是必须明确指定routing path的。
在你添加好mappings之后,创建当前索引的时候必须指定&routing=xxx,参数。这有个很大的好处就是你可以根据不同的业务维度自由调整分片策略。
上述内容就是ElasticSearch大数据分布式弹性搜索引擎该如何使用,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。