Linux如何安装和使用 Hadoop 大数据框架
近期有些网友想要了解的相关情况,小编通过整理给您分享一下。
随着大数据技术的快速发展,Hadoop作为一款开源的大数据处理框架,已经成为许多企业和开发者的首选工具。本文将详细介绍如何在Linux系统上安装和配置Hadoop,并分享一些基本的使用技巧,帮助你快速上手。
一、Hadoop简介
Hadoop是一个由Apache基金会开发的开源框架,主要用于分布式存储和处理大规模数据集。它的核心组件包括HDFS(Hadoop分布式文件系统)和MapReduce(分布式计算模型)。Hadoop的优势在于其高容错性和可扩展性,能够轻松处理PB级别的数据。
二、安装前的准备工作
在安装Hadoop之前,需要确保你的Linux系统满足以下条件:
- 操作系统:推荐使用Ubuntu或CentOS等主流Linux发行版。
- Java环境:Hadoop依赖于Java,因此需要安装JDK(Java Development Kit)。可以通过以下命令检查Java是否已安装:
java -version如果未安装,可以使用以下命令安装OpenJDK:
sudo apt-get install openjdk-8-jdk - SSH配置:Hadoop需要在集群节点之间进行无密码SSH通信。确保SSH已安装并配置:
sudo apt-get install sshssh-keygen -t rsa -P '' -f ~/.ssh/id_rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysssh localhost
三、安装Hadoop
- 下载Hadoop
访问Hadoop官网下载最新稳定版本,例如Hadoop 3.3.4:wget https://downloads.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz - 解压文件
将下载的压缩包解压到指定目录:tar -xzvf hadoop-3.3.4.tar.gz -C /opt/ - 配置环境变量
编辑~/.bashrc文件,添加以下内容:export HADOOP_HOME=/opt/hadoop-3.3.4export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin保存后执行以下命令使配置生效:
source ~/.bashrc - 配置Hadoop
进入Hadoop的配置目录$HADOOP_HOME/etc/hadoop,编辑以下文件:- hadoop-env.sh:设置Java环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 - core-site.xml:配置HDFS的默认文件系统:
fs.defaultFS hdfs://localhost:9000 - hdfs-site.xml:配置HDFS的存储目录:
dfs.replication 1 dfs.namenode.name.dir /opt/hadoop-3.3.4/data/namenode dfs.datanode.data.dir /opt/hadoop-3.3.4/data/datanode - mapred-site.xml:配置MapReduce框架:
mapreduce.framework.name yarn - yarn-site.xml:配置YARN资源管理器:
yarn.nodemanager.aux-services mapreduce_shuffle
- hadoop-env.sh:设置Java环境变量:
四、启动Hadoop
- 格式化HDFS
在首次启动Hadoop之前,需要格式化HDFS:hdfs namenode -format - 启动HDFS和YARN
使用以下命令启动HDFS和YARN:start-dfs.shstart-yarn.sh - 验证启动状态
使用jps命令查看Hadoop相关进程是否正常运行:jps如果看到
NameNode、DataNode、ResourceManager等进程,说明Hadoop已成功启动。
五、使用Hadoop
- 上传数据到HDFS
创建一个目录并将本地文件上传到HDFS:hdfs dfs -mkdir /inputhdfs dfs -put /path/to/local/file /input - 运行MapReduce任务
Hadoop自带了一些示例程序,可以通过以下命令运行WordCount任务:hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input /output - 查看任务结果
使用以下命令查看任务输出:hdfs dfs -cat /output/*
六、常见问题与解决方案
- HDFS无法启动
检查hdfs-site.xml中的目录权限,确保Hadoop用户有读写权限。 - MapReduce任务失败
查看任务日志,检查输入数据格式是否正确。 - YARN资源不足
调整yarn-site.xml中的资源分配参数,例如yarn.nodemanager.resource.memory-mb。
七、总结
通过以上步骤,你已经成功在Linux系统上安装并配置了Hadoop,并掌握了基本的使用方法。Hadoop的强大功能可以帮助你高效处理大规模数据,为你的数据分析和挖掘工作提供有力支持。如果你对Hadoop感兴趣,可以进一步学习其高级功能,例如Hive、HBase等生态系统组件。
希望本文对你有所帮助,祝你在大数据领域取得更多成就!
推荐阅读
-
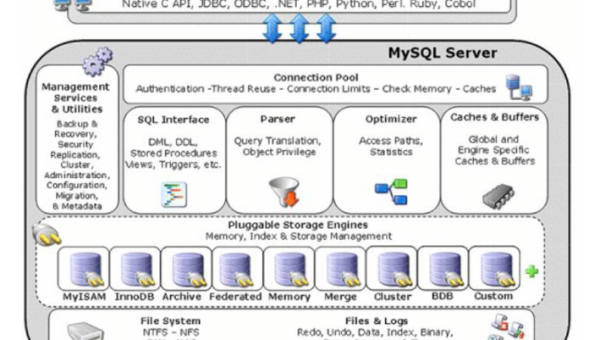
Retool 数据库连接:支持 MySQL、PostgreSQL 等多数据源配置
-
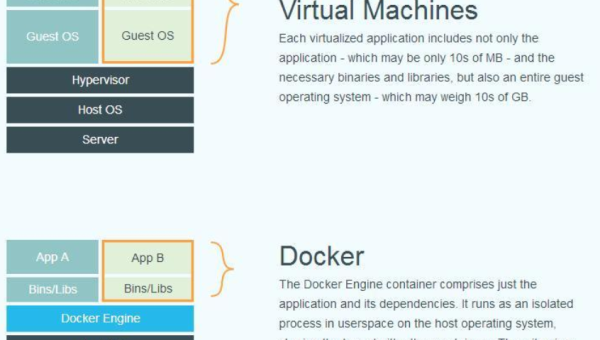
Docker 数据卷管理:持久化存储与容器间数据共享
-

Jupyter Notebook 性能优化:内核管理与大文件处理技巧
-
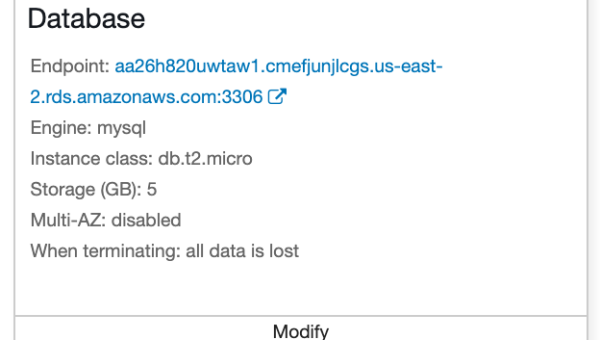
AWS Elastic Beanstalk 环境迁移:跨区域部署与数据同步方案
-
Vim 可视化块模式:列编辑与表格数据处理的终极技巧
-

如何理解处女座在数据整理中的精确
-

RStudio 数据分析全流程:从数据导入到动态报告生成的最佳实践
-

教育领域编程教学:Jupyter Notebook 与 RStudio 在数据分析课程中的应用
-
JUnit 5 参数化测试:数据驱动测试的实现与最佳实践
-
RStudio 数据可视化:ggplot2 与交互式图表制作全流程