JUnit 5 参数化测试:数据驱动测试的实现与最佳实践
JUnit 5 参数化测试:数据驱动测试的实现与最佳实践
在现代软件开发中,测试自动化是确保代码质量的关键环节。JUnit 5 作为 Java 世界的主流测试框架,提供了丰富的功能来支持各种测试场景。其中,参数化测试(Parameterized Testing)是一种高效的数据驱动测试方法,允许我们用不同的输入数据多次执行同一个测试用例。这对于提高测试覆盖率、减少重复代码以及发现隐藏的边界条件问题具有重要意义。
什么是参数化测试?
参数化测试是一种通过为测试方法提供不同输入数据集来执行多次测试的技术。传统的测试方法通常只能处理一种输入情况,而参数化测试则可以轻松扩展,覆盖多种场景。例如,假设我们要测试一个计算器的加法功能,传统方法可能需要为每个输入组合编写单独的测试用例,而参数化测试可以通过提供一个数据集,让测试用例自动遍历所有可能的输入组合。
JUnit 5 中的参数化测试实现
JUnit 5 提供了 @ParameterizedTest 注解,用于定义参数化测试方法。为了使用这个注解,我们需要导入 org.junit.jupiter.params 包。此外,JUnit 5 还支持多种数据提供方式,包括静态方法、文件、数据库查询等。
1. 使用 @ParameterizedTest 注解
在 JUnit 5 中,参数化测试的核心是 @ParameterizedTest 注解。我们可以在测试方法上添加这个注解,并使用 @ValueSource、@CsvSource 或 @MethodSource 等注解来提供数据源。
例如,以下代码展示了如何使用 @ValueSource 提供整数数据源:
import org.junit.jupiter.params.ParameterizedTest;import org.junit.jupiter.params.provider.ValueSource;public class CalculatorTest { @ParameterizedTest @ValueSource(ints = {0, 1, 2, 3, 4, 5}) void testAddition(int a) { Calculator calculator = new Calculator(); assertEquals(10 + a, calculator.add(10, a)); }}2. 使用 @CsvSource 提供 CSV 数据源
如果需要更复杂的测试数据,可以使用 @CsvSource 注解,从 CSV 文件或直接在代码中定义的 CSV 数据中获取输入。
import org.junit.jupiter.params.ParameterizedTest;import org.junit.jupiter.params.provider.CsvSource;public class CalculatorTest { @ParameterizedTest @CsvSource(value = {"10,5,15", "0,0,0", "-5,5,0"}, delimiter = ',') void testAddition(int a, int b, int expected) { Calculator calculator = new Calculator(); assertEquals(expected, calculator.add(a, b)); }}3. 使用 @MethodSource 提供动态数据源
对于需要动态生成数据的情况,可以使用 @MethodSource 注解,指定一个返回数据提供者的静态方法。
import org.junit.jupiter.params.ParameterizedTest;import org.junit.jupiter.params.provider.MethodSource;import java.util.stream.Stream;public class CalculatorTest { @ParameterizedTest @MethodSource("provideTestData") void testAddition(int a, int b, int expected) { Calculator calculator = new Calculator(); assertEquals(expected, calculator.add(a, b)); } static Stream provideTestData() { return Stream.of( Arguments.of(10, 5, 15), Arguments.of(0, 0, 0), Arguments.of(-5, 5, 0) ); }}参数化测试的最佳实践
1. 合理组织测试数据
测试数据的组织直接影响测试的可维护性和扩展性。建议将测试数据与测试逻辑分离,例如将数据存储在独立的文件或数据库中。这样,当数据需要更新时,无需修改测试代码。
2. 命名清晰
为每个测试方法和数据提供者方法选择有意义的名称,以便其他开发者能够快速理解测试的目的和数据来源。
3. 控制数据量
虽然参数化测试可以处理大量数据,但过大的数据集可能会导致测试执行时间过长。建议根据实际需求合理控制数据量,优先覆盖核心场景和边界条件。
4. 处理异常情况
在参数化测试中,某些数据可能会导致测试失败或抛出异常。建议为这些情况编写专门的测试用例,并使用 JUnit 5 的 @TestFactory 或 @DynamicTest 等功能进行动态测试。
5. 结合断言库
为了提高测试的可读性和维护性,可以结合断言库(如 AssertJ)来编写更强大的断言逻辑。
总结
JUnit 5 的参数化测试功能为数据驱动测试提供了强大的支持,通过灵活的数据提供方式和简洁的注解语法,显著提高了测试效率和代码质量。在实际应用中,合理组织测试数据、选择合适的注解和断言库,能够帮助我们更好地利用参数化测试的优势,确保软件的稳定性和可靠性。
通过遵循上述最佳实践,开发者可以在项目中充分利用 JUnit 5 的参数化测试功能,编写高效、可维护的测试代码,为软件质量保驾护航。
推荐阅读
-
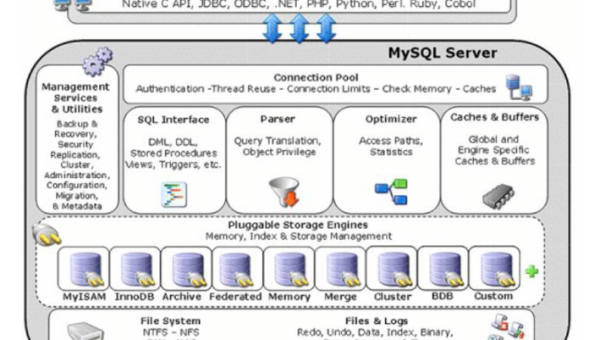
Retool 数据库连接:支持 MySQL、PostgreSQL 等多数据源配置
-
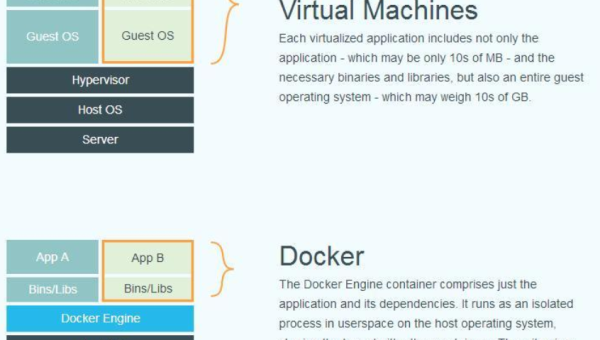
Docker 数据卷管理:持久化存储与容器间数据共享
-

JUnit 5 扩展机制:自定义测试规则与报告生成
-

Jupyter Notebook 性能优化:内核管理与大文件处理技巧
-
AWS Elastic Beanstalk 环境迁移:跨区域部署与数据同步方案
-
JUnit 5 与 Spring Boot 整合:单元测试与集成测试最佳实践
-
Vim 可视化块模式:列编辑与表格数据处理的终极技巧
-
JUnit 5 动态测试:运行时生成测试用例的实现原理
-
JUnit 5 扩展开发:自定义测试报告生成器与持续集成集成
-

JUnit 5 参数化测试进阶:CSV 文件与 JSON 数据驱动实现