Java 正则表达式URL 匹配与源码全解析
在 web 应用开发中,我们经常需要对 url 进行格式验证。今天我们结合 java 的 pattern 和 matcher 类,深入理解正则表达式在实际应用中的强大功能,并剖析一段实际的 java 示例源码。
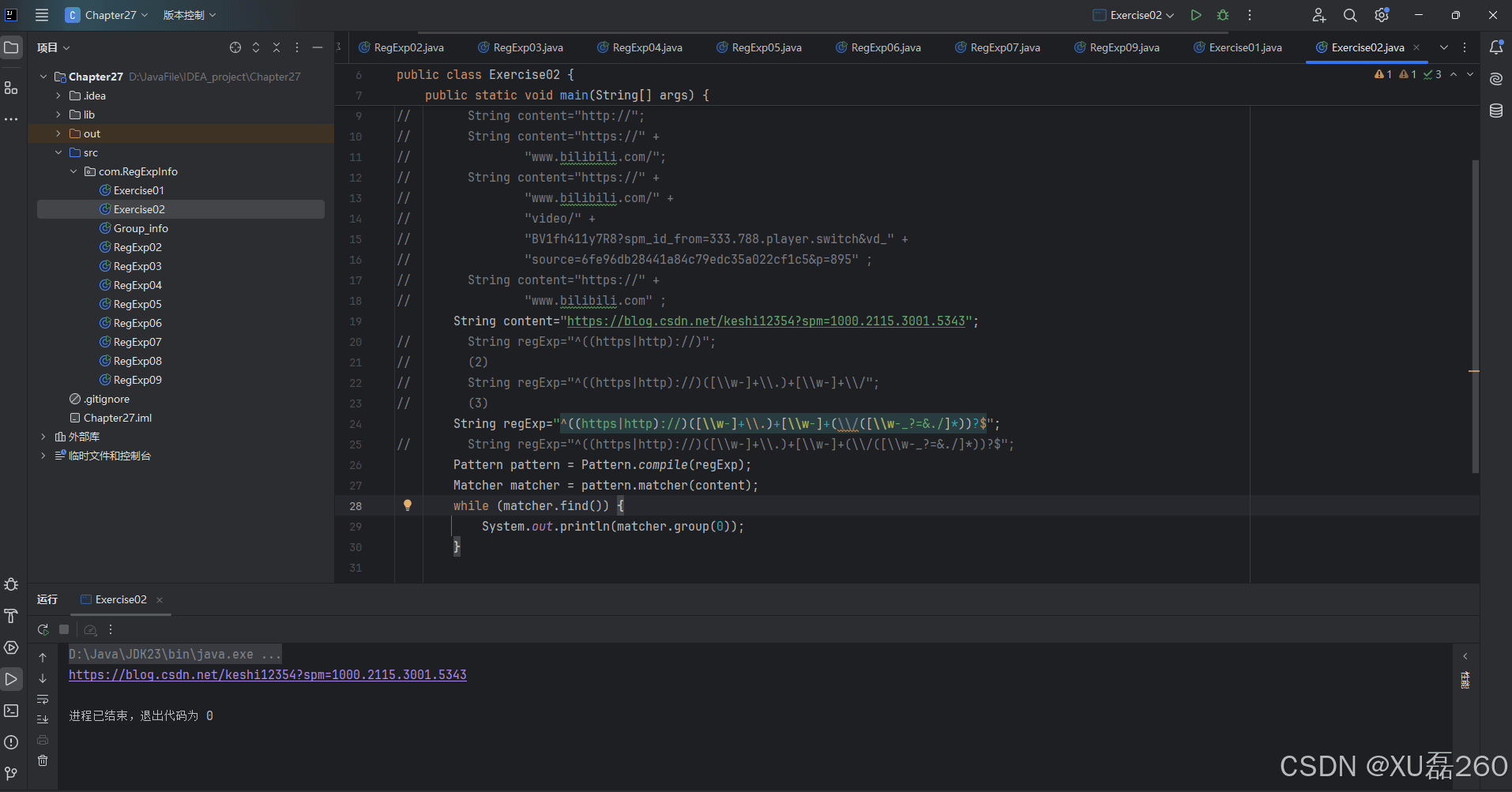
package com.regexpinfo;
import java.util.regex.matcher;
import java.util.regex.pattern;
public class exercise02 {
public static void main(string[] args) {
// string content="https://";
// string content="http://";
// string content="https://" +
// "www.bilibili.com/";
// string content="https://" +
// "www.bilibili.com/" +
// "video/" +
// "bv1fh411y7r8?spm_id_from=333.788.player.switch&vd_" +
// "source=6fe96db28441a84c79edc35a022cf1c5&p=895" ;
// string content="https://" +
// "www.bilibili.com" ;
string content="https://blog.csdn.net/keshi12354?spm=1000.2115.3001.5343";
// string regexp="^((https|http)://)";
// (2)
// string regexp="^((https|http)://)([\\w-]+\\.)+[\\w-]+\\/";
// (3)
string regexp="^((https|http)://)([\\w-]+\\.)+[\\w-]+(\\/([\\w-_?=&./]*))?$";
// string regexp="^((https|http)://)([\\w-]+\\.)+[\\w-]+(\\/([\\w-_?=&./]*))?$";
pattern pattern = pattern.compile(regexp);
matcher matcher = pattern.matcher(content);
while (matcher.find()) {
system.out.println(matcher.group(0));
}
}
}
1.正则表达式分解:
分布实现:
1. 基础协议匹配(1)
string regexp="^((https|http)://)";
功能:只匹配url开头的协议部分
匹配内容:http://或https://
结构:
^表示字符串开始
(https|http)匹配"https"或"http"
://匹配协议分隔符
目的:先确保能正确识别url的协议部分
2. 添加域名匹配(2)
string regexp="^((https|http)://)([\\w-]+\\.)+[\\w-]+\\/";
新增功能:在协议后添加域名和路径的基本匹配
匹配内容:如http://example.com/
新增结构:
([\\w-]+\\.)+匹配一个或多个域名部分(如"www."或"sub.")
\\w匹配单词字符(字母、数字、下划线)
-匹配连字符
+表示一次或多次
\\.匹配点号
[\\w-]+匹配顶级域名(如"com")
\\/匹配结尾的斜杠
目的:扩展匹配完整的域名结构
3. 添加路径和查询参数匹配(3)
string regexp="^((https|http)://)([\\w-]+\\.)+[\\w-]+(\\/([\\w-_?=&./]*))?$";
新增功能:支持可选的路径和查询参数
匹配内容:如http://example.com/path?param=value
新增结构:
(\\/([\\w-_?=&./]*))?
\\/匹配路径开始的斜杠
[\\w-_?=&./]*匹配路径和查询参数
包含字母、数字、下划线、连字符、问号、等号、&、点和斜杠
?表示整个路径部分是可选的
$表示字符串结束
目的:使正则表达式能够匹配带路径和参数的完整url
4. 最终优化版本
string regexp="^((https|http)://)?([\\w-]+\\.)+[\\w-]+(\\/([\\w-_?=&./]*))?$";
关键改进:使协议部分变为可选
匹配内容:现在可以匹配:
带协议的url:http://example.com/path
不带协议的url:example.com/path
修改点:
在协议部分((https|http)://)后添加了?使其变为可选
目的:提高正则表达式的灵活性,适应更多使用场景
5.设计思想总结
渐进式开发:从简单到复杂逐步构建正则表达式
模块化设计:每个部分都有明确的功能划分(协议、域名、路径)
灵活性增强:通过添加可选标记(?)使表达式更通用
边界明确:始终使用^和$确保匹配整个字符串
字符集合理定义:使用[\w-]等字符集准确描述允许的字符
这种分步构建的方法不仅使正则表达式更易于理解和维护,也方便在开发过程中逐步测试每个部分的匹配效果。
到此这篇关于java 正则表达式综合实战:url 匹配与源码解析的文章就介绍到这了,更多相关java正则表达式url 匹配内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24