Netty核心11-HttpRequestDecoder源码
上篇讲解了 ,例子里面实现了基本的Get/Post请求,如何获取请求uri,headers,body等等。看懂这个例子基本上就可以用来做大部分的http请求了。
本篇就来讲解,到底netty是如何实现的,是不是我们自己也可以利用netty的核心功能,自己实现呢?
答案是:当然可以,我们用netty实现http服务器,只用了三个类HttpRequest decode r,HttpObjectAggregator,HttpResponseEncoder。这三个类是实现了netty的核心类 message ToMessageEncoder,MessageToMessageDecoder。
这三个类只是扩展了,并不属于netty核心框架里面,我们当然可以自己扩展。
希望看完本篇,读者自己也能自己扩展。
首先http请求的过程是什么呢?
也就是用土话讲,http请求发送了一段有格式的请求数据到服务端,服务端按照规定的格式解析,解析成对应的数据。
返回的时候,将内容解析成对应格式的数据返回给客户端。
那么这个有格式的数据,分为Http请求报文和http响应报文。
Http请求报文
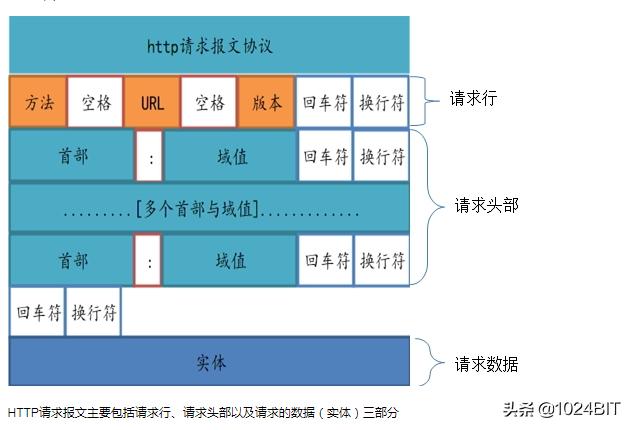
http请求报文
Http响应报文
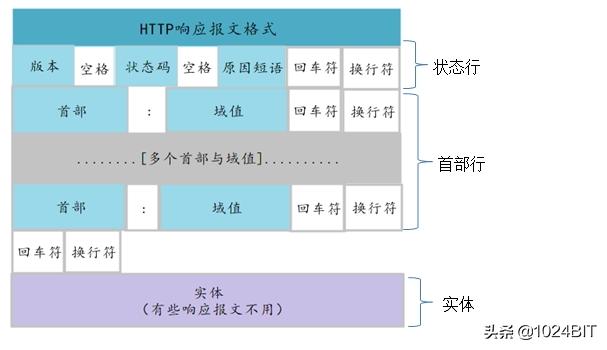
http响应报文
也就是HttpRequestDecoder,HttpObjectAggregator,HttpResponseEncoder这三个类只做了一件事情就是解析和编码这两段报文而已。
到这里,我自己当然可以简易实现呀,我只要按照规定格式解析和组合就可以了。
接下来就看netty是如何解析报文。
HttpRequestDecoder
功能是将请求内容ByteBuf解析成对应Http请求体,DefaultHttpRequest,DefaultFullHttpRequest,DefaultHttpContent,DefaultLastHttpContent等等。
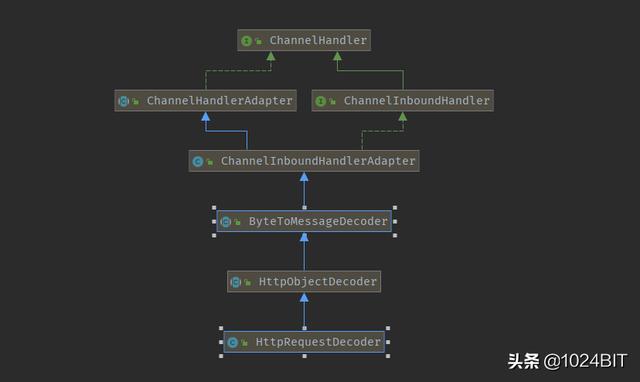
从关系图中可以看出,HttpRequestDecoder是实现了ByteToMessageDecoder。
ByteToMessageDecoder是将ByteBuf转化成POJO,这个前面已经详细讲解了请参考
首先来看HttpObjectDecoder的成员变量信息
public abstract class HttpObjectDecoder extends ByteToMessageDecoder {
private static final String EMPTY_VALUE = "";
//最大的chunksize大小
private final int maxChunkSize;
//是否支持chunk
private final boolean chunkedSupported;
//校验头部
protected final boolean validateHeaders;
//头部解析器
private final HeaderParser headerParser;
//每一行数据解析器
private final LineParser lineParser;
//http消息
private HttpMessage message;
private long chunkSize;
private long contentLength = Long.MIN_VALUE;
private volatile boolean resetRequested;
// These will be updated by splitHeader(...)
private CharSequence name;
private CharSequence value;
private LastHttpContent trailer;
/**
* The internal state of {@link HttpObjectDecoder}.
* Internal use only.
*/
private enum State {
SKIP_CONTROL_CHARS,
READ_INITIAL,
READ_HEADER,
READ_VARIABLE_LENGTH_CONTENT,
READ_FIXED_LENGTH_CONTENT,
READ_CHUNK_SIZE,
READ_CHUNKED_CONTENT,
READ_CHUNK_DELIMITER,
READ_CHUNK_FOOTER,
BAD_MESSAGE,
UPGRADED
}
private State currentState = State.SKIP_CONTROL_CHARS;
这里讲解下chunk
当客户端向服务器请求一个静态页面或者一张图片时,服务器可以很清楚的知道内容大小,然后通过Content-Length消息首部字段告诉客户端需要接收多少数据。但是如果是动态页面等时,服务器是不可能预先知道内容大小,这时就可以使用Transfer-Encoding:chunk模式来传输数据了。即如果要一边产生数据,一边发给客户端,服务器就需要使用”Transfer-Encoding: chunked”这样的方式来代替Content-Length。
如果是动态页面等等服务器是不可能预先知道内容大小的就使用chunk。
chunk的解析和接下来知道内容长度的解析类似。如果感兴趣可以自己分析,不属于本篇重点。
- validateHeaders:是否需要校验头部数据信息
- headerParser:头部参数解析器,解析http报文,解析出头部报文信息
- lineParser:继承了HeaderParser,多了一个异常方法。处理起来还是headerParser
- HttpMessage:就是解析后的http消息
- name,value:就是解析的头部名称和值
- State:是解析时候的状态,就是解析到了哪一步。初始化为State.SKIP_CONTROL_CHARS就是判断解析的字符串格式是否正确。
回到前一篇关于 ByteToMessageDecoder,它有一个抽象方法
protected void decode(ChannelHandlerContext ctx, ByteBuf buffer, List
解析Bytebuf并且返回到out里面,如果解析完毕或者等等其他条件解析就会结束。
重点看decode方法。
这段方法很长,简单讲些主要功能。
就是从ByteBuf里面一步步的按照HttpRequest报文来解析数据。
例子报文数据如下
POST / HTTP/1.1
Content-Type: text/plain
User-Agent: PostmanRuntime/7.26.3
Accept : */*
Cache-Control : no-cache
Postman-Token: 35632bdf-fae2-4e56-b7ef-89ab83d97b9a
Host: localhost :8080
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Content-Length: 21
{
"test":1212
}
1.currentState:SKIP_CONTROL_CHARS
检查字符串是否合理
private static boolean skipControl Character s(ByteBuf buffer) {
boolean skiped = false;
final int wIdx = buffer.writerIndex();
int rIdx = buffer.readerIndex();
while (wIdx > rIdx) {
int c = buffer.getUnsignedByte(rIdx++);
if (!Character.isISOControl(c) && !Character.isWhitespace(c)) {
rIdx--;
skiped = true;
break;
}
}
buffer.readerIndex(rIdx);
return skiped;
}
Character.isISOControl(c) && !Character.isWhitespace(c):就是检测字符是否为ISO类型,是否不是空白字符。
如果是正常字符,不用跳过。修改currentState = State.READ_INITIAL;
2.currentState:READ_INITIAL
读取报文的初始化信息也就是请求的类型,http类型,请求地址,也就是例子中的
POST / HTTP/1.1
AppendableCharSequence line = lineParser.parse(buffer);
if (line == null) {
return;
}
String[] initialLine = splitInitialLine(line);
if (initialLine.length < 3) {
// Invalid initial line - ignore.
currentState = State.SKIP_CONTROL_CHARS;
return;
}
message = createMessage(initialLine);
currentState = State.READ_HEADER;
lineParser.parse(buffer);
这行就是只读取一行数据。例如读到GET /test HTTP/1.1就结束了。
@Override
protected HttpMessage createMessage(String[] initialLine) throws Exception {
return new DefaultHttpRequest(
HttpVersion.valueOf(initialLine[2]),
HttpMethod.valueOf(initialLine[0]), initialLine[1], validateHeaders);
}
读取了第一行报文之后,返回了DefaultHttpRequest
此时修改currentState = State.READ_HEADER;开始读头部信息
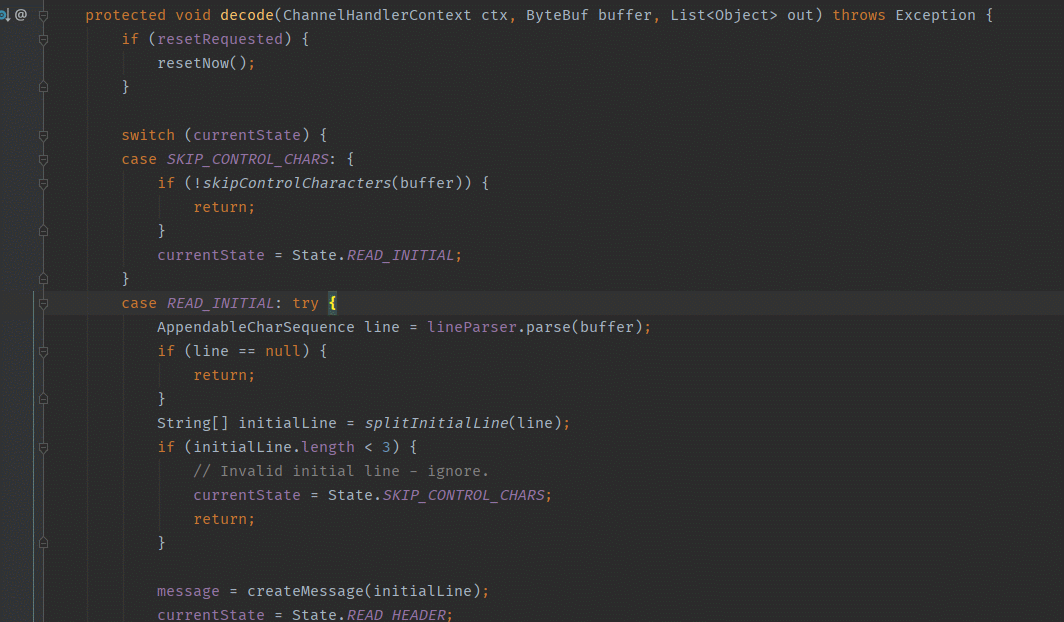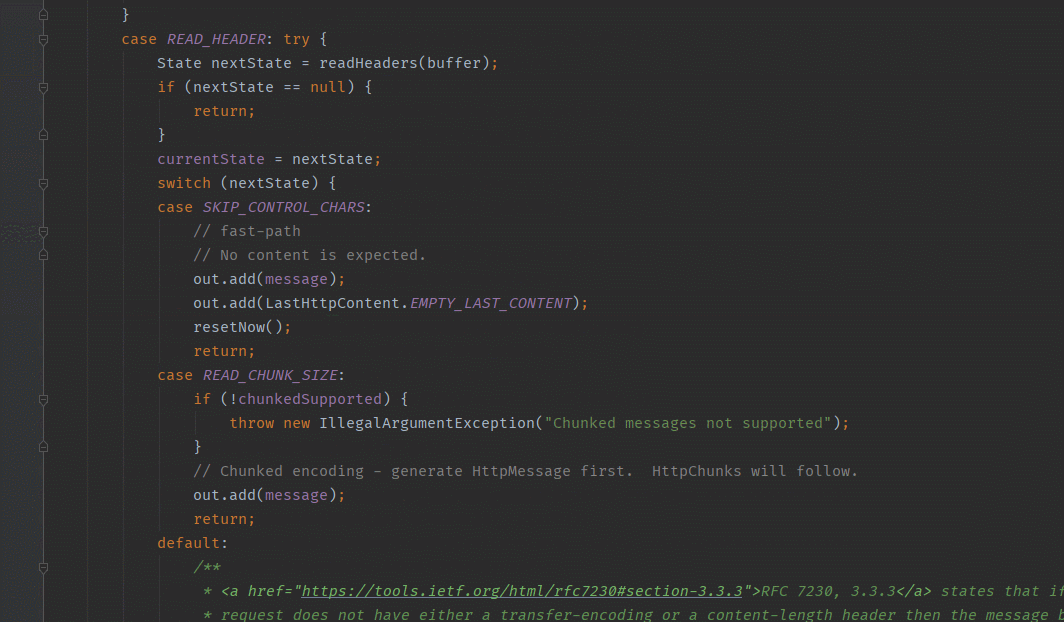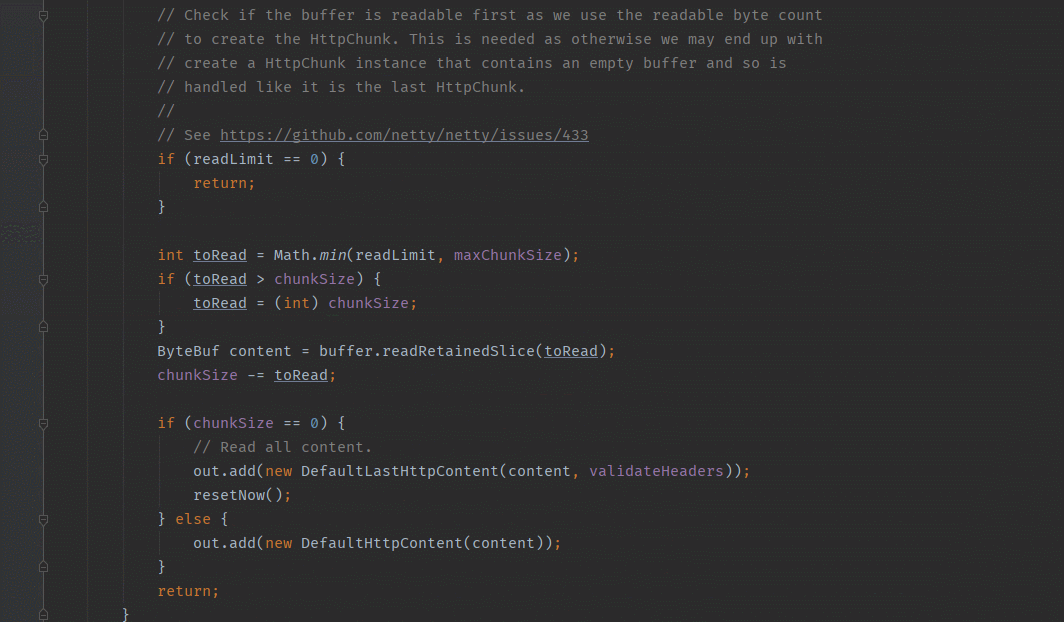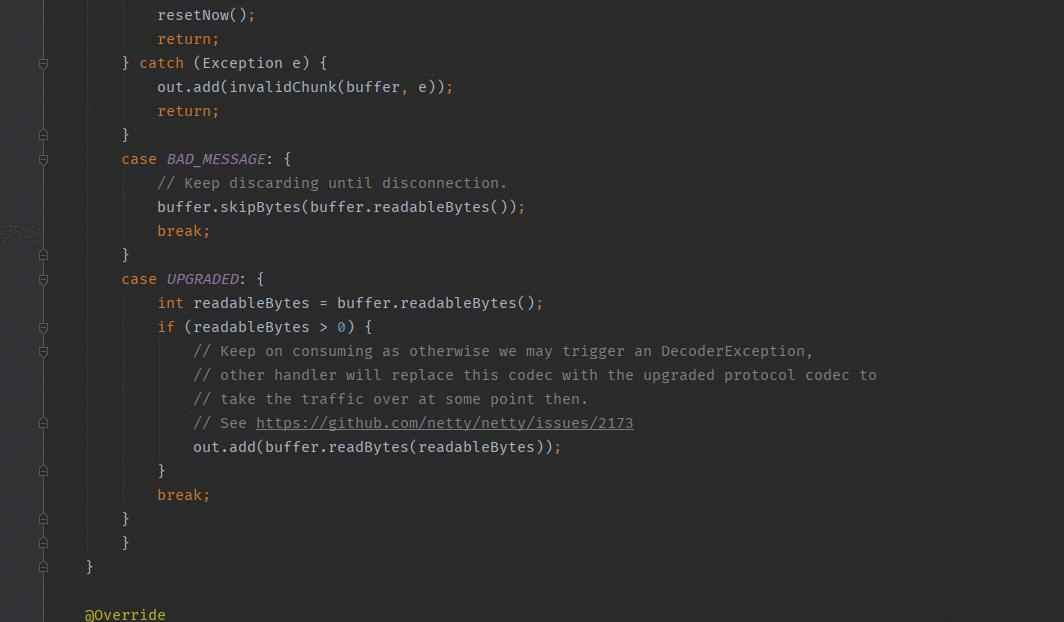
3.currentState:READ_HEADER
State nextState = readHeaders(buffer);
if (nextState == null) {
return;
}
currentState = nextState;
switch (nextState) {
case SKIP_CONTROL_CHARS:
// fast-path
// No content is expected.
out.add(message);
out.add(LastHttpContent.EMPTY_LAST_CONTENT);
resetNow();
return;
case READ_CHUNK_SIZE:
if (!chunkedSupported) {
throw new IllegalArgumentException("Chunked messages not supported");
}
// Chunked encoding - generate HttpMessage first. HttpChunks will follow.
out.add(message);
return;
default:
/**
* RFC 7230, 3.3.3 states that if a
* request does not have either a transfer-encoding or a content-length header then the message body
* length is 0. However for a response the body length is the number of octets received prior to the
* server closing the connection. So we treat this as variable length chunked encoding.
*/
long contentLength = contentLength();
if (contentLength == 0 || contentLength == -1 && isDecodingRequest()) {
out.add(message);
out.add(LastHttpContent.EMPTY_LAST_CONTENT);
resetNow();
return;
}
assert nextState == State.READ_FIXED_LENGTH_CONTENT ||
nextState == State.READ_VARIABLE_LENGTH_CONTENT;
out.add(message);
if (nextState == State.READ_FIXED_LENGTH_CONTENT) {
// chunkSize will be decreased as the READ_FIXED_LENGTH_CONTENT state reads data chunk by chunk.
chunkSize = contentLength;
}
// We return here, this forces decode to be called again where we will decode the content
return;
}
private State readHeaders(ByteBuf buffer) {
final HttpMessage message = this.message;
final HttpHeaders headers = message.headers();
AppendableCharSequence line = headerParser.parse(buffer);
if (line == null) {
return null;
}
if (line.length() > 0) {
do {
char firstChar = line.charAt(0);
if (name != null && (firstChar == ' ' || firstChar == '\t')) {
//please do not make one line from below code
//as it breaks +XX:OptimizeStringConcat optimization
String trimmedLine = line.toString().trim();
String valueStr = String.valueOf(value);
value = valueStr + ' ' + trimmedLine;
} else {
if (name != null) {
headers.add(name, value);
}
splitHeader(line);
}
line = headerParser.parse(buffer);
if (line == null) {
return null;
}
} while (line.length() > 0);
}
// Add the last header.
if (name != null) {
headers.add(name, value);
}
// reset name and value fields
name = null;
value = null;
State nextState;
if (isContentAlwaysEmpty(message)) {
HttpUtil.setTransferEncodingChunked(message, false);
nextState = State.SKIP_CONTROL_CHARS;
} else if (HttpUtil.isTransferEncodingChunked(message)) {
nextState = State.READ_CHUNK_SIZE;
} else if (contentLength() >= 0) {
nextState = State.READ_FIXED_LENGTH_CONTENT;
} else {
nextState = State.READ_VARIABLE_LENGTH_CONTENT;
}
return nextState;
}
readHeaders:一行行解析头部信息当解析一行数据没有的时候就结束解析,解析的数据也就是上面的
Content-Type: text/plain
User-Agent: PostmanRuntime/7.26.3
Accept: */*
Cache-Control: no-cache
Postman-Token: 35632bdf-fae2-4e56-b7ef-89ab83d97b9a
Host: localhost:8080
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Content-Length: 21
if (isContentAlwaysEmpty(message)) {
HttpUtil.setTransferEncodingChunked(message, false);
nextState = State.SKIP_CONTROL_CHARS;
} else if (HttpUtil.isTransferEncodingChunked(message)) {
nextState = State.READ_CHUNK_SIZE;
} else if (contentLength() >= 0) {
nextState = State.READ_FIXED_LENGTH_CONTENT;
} else {
nextState = State.READ_VARIABLE_LENGTH_CONTENT;
}
readHeaders解析完headers之后,判断message是不是一直是空,如果是就跳到SKIP_CONTROL_CHARS解析内容。
如果message是Chunked也就是上面提到的headers中使用Transfer-Encoding: chunked,就跳到READ_CHUNK_SIZE开始读CHUNK。
如果Content-Length大于0,表示有body则跳到READ_FIXED_LENGTH_CONTENT,读取固定长度内容。否则跳到READ_VARIABLE_LENGTH_CONTENT读取可变的内容。
我们这里Content-Length: 21表示有固定内容,因此nextState = State.READ_FIXED_LENGTH_CONTENT
long contentLength = contentLength();
if (contentLength == 0 || contentLength == -1 && isDecodingRequest()) {
out.add(message);
out.add(LastHttpContent.EMPTY_LAST_CONTENT);
resetNow();
return;
}
如果内容长度为空,out输出message,和LastHttpContent(empty)
4.currentState:READ_FIXED_LENGTH_CONTENT
读取
int readLimit = buffer.readableBytes();
// Check if the buffer is readable first as we use the readable byte count
// to create the HttpChunk. This is needed as otherwise we may end up with
// create a HttpChunk instance that contains an empty buffer and so is
// handled like it is the last HttpChunk.
//
// See
if (readLimit == 0) {
return;
}
int toRead = Math.min(readLimit, maxChunkSize);
if (toRead > chunkSize) {
toRead = (int) chunkSize;
}
ByteBuf content = buffer.readRetainedSlice(toRead);
chunkSize -= toRead;
if (chunkSize == 0) {
// Read all content.
out.add(new DefaultLastHttpContent(content, validateHeaders));
resetNow();
} else {
out.add(new DefaultHttpContent(content));
}
如果chunkSize==0表示固定的长度的内容,那么就是返回DefaultLastHttpContent。
关于Chunk方面的解析,和这里是类似的,大家可以自行分析。
回到上面的报文HttpRequestDecoder讲它解析成三部分。
第一部分请求报文请求行
POST / HTTP/1.1
返回的是DefaultHttpRequest
第二部分请求报文头部DefaultHttpRequest.headers
Content-Type: text/plain
User-Agent: PostmanRuntime/7.26.3
Accept: */*
Cache-Control: no-cache
Postman-Token: 35632bdf-fae2-4e56-b7ef-89ab83d97b9a
Host: localhost:8080
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Content-Length: 21
第三部分请求内容
{
"test":1212
}
返回的是DefaultLastHttpContent
关于DefaultLastHttpContent,HttpMessage,DefaultHttpRequest关于http的相关请求类,这里我不打算讲解。我们知道知道这些类用来处理http请求相关,如何处理使用,我们只要看下接口就知道了。
到此
HttpRequestDecoder如果解析ByteBuf到响应的Http请求类,已经讲解完毕了,其实无非就是解析报文成对应的类即可,就这么简单,就这么理解就行了。
解析之后我们有两个类,一个是请求消息类HttpMessage,一个是请求内容类HttpContent,在netty里面使用
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg ) throws Exception {
//判断是不是http请求
if(msg instanceof HttpRequest){
HttpRequest httpRequest = (HttpRequest) msg;
parseUri(httpRequest);
parseHttpMethod(httpRequest);
parseHttpHeaders(httpRequest);
parseBody(httpRequest);
FullHttpResponse res = new DefaultFullHttpResponse(HTTP_1_1, OK, Unpooled.wrappedBuffer("ok".getBytes()));
HttpUtil.setContentLength(res, res.content().readableBytes());
ctx.writeAndFlush(res);
}
super.channelRead(ctx, msg);
}
只有一个msg对象,那么我们需要将HttpMessage与HttpContent聚合起来。那么netty是如何聚合的呢?
下一节讲解HttpObjectAggregator聚合HttpMessage与HttpContent
推荐阅读
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24