为什么CUDA显示显存足够却仍然报错?
在使用CUDA进行深度学习或高性能计算时,许多用户都遇到过这样一个令人困惑的情况:系统显示显存容量充足,程序却依然报出“out of memory”错误,这种现象不仅影响工作效率,也让人对硬件和软件的可靠性产生疑虑,本文将从技术角度分析这一问题成因,并提供切实可行的解决方案。
导致显存充足却报错的主要原因有以下几点:

显存碎片化
CUDA显存管理机制中存在显存碎片问题,虽然显存总容量充足,但可用显存被分割成多个不连续的小块,当程序申请一块较大的连续显存时,即使总空闲显存大于申请量,也可能因找不到足够大的连续空间而失败,这种情况在长时间运行多个CUDA程序或频繁分配释放显存的环境中尤为常见。
显存管理开销
CUDA运行时和深度学习框架(如PyTorch、TensorFlow)本身需要占用部分显存用于管理内存分配、内核执行等任务,框架的缓存分配器会预留一部分显存,这部分空间用户不可见,但会减少实际可用显存。
硬件架构限制
不同代际的GPU架构对显存管理方式存在差异,某些旧款GPU可能存在显存分配粒度问题,导致实际可用显存小于标称值,同时多GPU系统中,NVLink或PCIe拓扑结构可能影响显存池化效率。
软件配置因素
深度学习框架的默认配置可能不是最优选择,例如TensorFlow的显存分配策略分为“按需分配”和“预分配”两种模式,不当配置可能导致显存利用率低下,CUDA版本与GPU驱动程序的兼容性问题也可能引发异常。
针对这些问题,可以采取以下解决方案:
优化显存分配策略
对于PyTorch用户,可使用torch.cuda.empty_cache()及时清理无用缓存,或通过设置max_split_size_mb参数调整分配器行为,TensorFlow用户可通过tf.config.experimental.set_memory_growth启用动态显存增长模式,避免一次性占用过多显存。
调整模型计算配置
减小训练时的批次大小(batch size)是最直接的显存优化方法,使用梯度累积技术,通过多次小批次计算累积梯度再更新参数,实现在有限显存下训练大模型,选择更高效的优化器,如AdaFactor代替Adam,也能显著减少显存占用。
启用内存节省技术
混合精度训练(AMP)同时使用FP16和FP32数据类型,既能保持模型精度,又能大幅降低显存使用量,激活检查点技术(activation checkpointing)通过牺牲计算时间换取显存空间,在前向传播中只保存部分节点的激活值,其余节点在反向传播时重新计算。
系统级优化
定期更新GPU驱动程序与CUDA工具包,确保获得最新的性能优化和错误修复,对于多卡环境,合理设置环境变量CUDA_VISIBLE_DEVICES可以控制可见GPU设备,避免资源冲突,在Docker容器中运行CUDA程序时,注意正确挂载GPU设备并配置相应的运行时参数。
诊断工具的使用
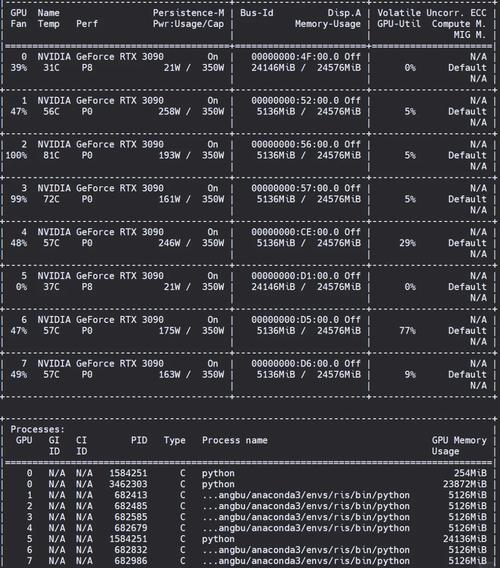
利用nvidia-smi命令实时监控显存使用情况,特别是使用nvidia-smi -l 1连续刷新显示功能,Nsight Systems和Nsight Compute工具可以提供更详细的显存分配分析,PyTorch的torch.cuda.memory_summary()和TensorFlow的tf.config.experimental.get_memory_info()都是框架内置的有效诊断工具。
从工程实践角度看,显存管理是一个需要综合考虑硬件特性、软件配置和应用需求的系统性问题,单纯依赖硬件扩容往往不是最优解,通过算法优化和系统调优往往能获得更好的性价比,在实际开发中,建议建立显存使用监控机制,提前识别潜在问题;同时保持代码的灵活性,使关键参数(如批次大小、精度设置)能够快速调整以适应不同硬件环境。
显存充足却报错的问题反映了CUDA生态系统的复杂性,但通过系统性的排查和优化,大多数问题都能得到有效解决,良好的开发习惯和适当的调试工具使用,将帮助用户更高效地利用GPU资源。