如何解决CUDA使用中的常见报错问题?
近期有些网友想要了解如何解决CUDA使用中的常见报错问题的相关情况,小编通过整理给您分析,根据自身经验分享有关知识。
在GPU编程领域,CUDA技术凭借其高效的并行计算能力,成为开发者加速计算任务的首选工具,无论是新手还是经验丰富的工程师,在实际开发中难免遇到各种报错信息,如何快速定位并解决这些问题,直接影响开发效率和项目进度,本文将围绕CUDA开发中常见的报错类型展开分析,并提供可落地的解决方案。
**一、环境配置引发的报错
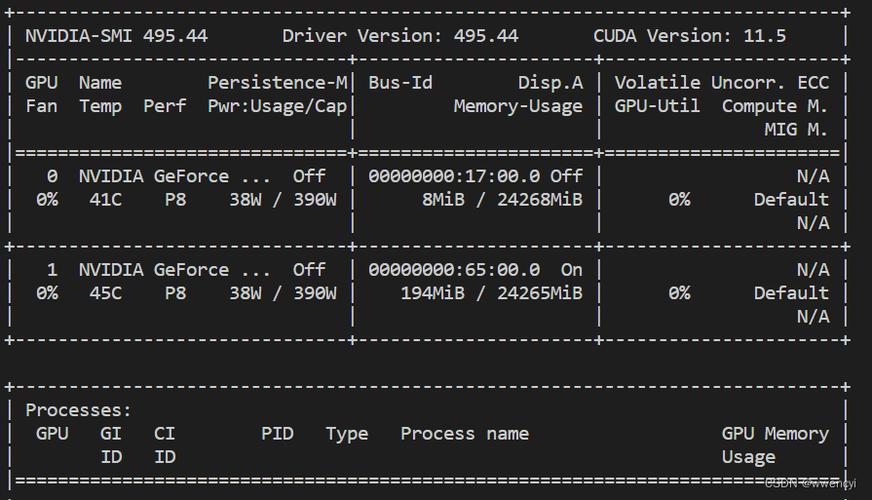
CUDA对运行环境的依赖性强,版本不匹配或驱动问题可能导致程序无法启动,安装CUDA Toolkit时若未选择与显卡驱动兼容的版本,执行nvidia-smi命令后可能显示CUDA driver version is insufficient错误。

解决方案:
1、通过NVIDIA官网查询驱动与CUDA版本的对应关系;
2、使用以下命令验证环境配置:
nvcc --version # 查看CUDA编译器版本nvidia-smi # 确认驱动支持的CUDA最高版本
3、优先通过官方脚本安装驱动,避免第三方软件导致依赖冲突。
**二、内存管理导致的崩溃
GPU内存分配错误是CUDA报错的高发区,典型场景包括:
越界访问:内核函数中线程访问超出数组声明的内存空间;
内存泄漏:未释放已分配的显存,导致后续操作因out of memory中断;
主机与设备通信错误:错误使用cudaMemcpy函数方向参数。
调试技巧:
- 使用cuda-memcheck工具检测内存越界:
cuda-memcheck ./your_program
- 在代码中插入检查点:
cudaError_t err = cudaMalloc(&dev_ptr, size);if (err != cudaSuccess) { printf("Error: %s\n", cudaGetErrorString(err));}**三、内核函数执行异常
内核函数(Kernel)设计不当可能引发隐式错误,
1、线程数超出硬件限制:单个Block线程数超过1024(常见于老架构GPU);
2、共享内存超限:未根据SM(流多处理器)的共享内存容量调整配置;
3、同步错误:在非并行代码区域误用__syncthreads()。
规避方案:
- 启动内核前添加静态断言检查:
static_assert(THREADS_PER_BLOCK <= 1024, "Threads exceed limit");
- 通过运行时API动态获取设备属性:
cudaDeviceProp prop;cudaGetDeviceProperties(&prop, 0);int max_threads = prop.maxThreadsPerBlock;
**四、硬件兼容性问题
不同GPU架构(如Ampere、Turing、Pascal)对CUDA指令集的支持存在差异,若在编译时未指定正确的计算能力(Compute Capability),可能触发no kernel image available for execution错误。
应对策略:
1、使用-arch=compute_XX和-code=sm_XX编译参数指定目标架构;
2、针对多设备部署,启用PTX兼容模式:
nvcc -gencode arch=compute_50,code=sm_50 -gencode arch=compute_60,code=sm_60
**五、调试工具与日志分析
成熟的调试工具能显著缩短问题定位时间:
Nsight Systems:分析内核执行时间线,识别性能瓶颈;
cuda-gdb:支持断点调试和变量监控;
自定义日志:在内核函数前后插入printf语句(需启用-G编译选项)。
**个人观点
处理CUDA报错的核心在于建立系统化调试思维:从环境验证到内存分析,从代码审查到硬件适配,每一步都需结合工具链进行交叉验证,与其依赖碎片化的问题搜索,不如深入理解CUDA执行模型与硬件架构的交互逻辑——这或许才是突破报错困局的终极解法。