elasticsearch索引index之Mapping实现关系结构示例
目录
- Mapping的实现关系结构
- Mapper的三类
- parse方法
- 部分Field
- 总结
Mapping的实现关系结构
Lucene索引的一个特点就filed,索引以field组合。这一特点为索引和搜索提供了很大的灵活性。elasticsearch则在Lucene的基础上更近一步,它可以是 no scheme。实现这一功能的秘密就Mapping。Mapping是对索引各个字段的一种预设,包括索引与分词方式,是否存储等,数据根据字段名在Mapping中找到对应的配置,建立索引。这里将对Mapping的实现结构简单分析,Mapping的放置、更新、应用会在后面的索引fenx中进行说明。

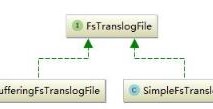
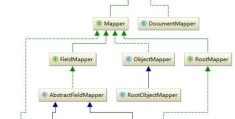
这只是Mapping中的一部分内容。Mapping扩展了lucene的filed,定义了更多的field类型既有Lucene所拥有的string,number等字段又有date,IP,byte及geo的相关字段,这也是es的强大之处。如上图所示,可以分为两类,mapper与documentmapper,前者是所有mapper的父接口。而DocumentMapper则是Mapper的集合,它代表了一个索引的mapper定义。
Mapper的三类
第一类就是核心field结构FileMapper—>AbstractFieldMapper—>StringField这种核心数据类型,它代表了一类数据类型,如字符串类型,int类型这种;
第二类是Mapper—>ObjectMapper—>RootObjectMapper,object类型的Mapper,这也是elasticsearch对lucene的一大改进,不想lucene之支持基本数据类型;
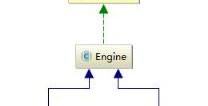
最后一类是Mapper—>RootMapper—>IndexFieldMapper这种类型,只存在于根Mapper中的一种Mapper,如IdFieldMapper及图上的IndexFieldM if (source.source() != null && source.source().length() == 0) { throw new MapperParsingException("failed to parse, document is empty"); } throw new MapperParsingException("failed to parse", e); } finally { // only close the parser when its not provided externally if (source.parser() == null && parser != null) { parser.close(); } } // reverse the order of docs for nested docs support, parent should be last if (context.docs().size() > 1) { Collections.reverse(context.docs()); } // apply doc boost if (context.docBoost() != 1.0f) { Set<String> encounteredFields = Sets.newHashSet(); for (ParseContext.Document doc : context.docs()) { encounteredFields.clear(); for (IndexableField field : doc) { if (field.fieldType().indexed() && !field.fieldType().omitNorms()) { if (!encounteredFields.contains(field.name())) { ((Field) field).setBoost(context.docBoost() * field.boost()); encounteredFields.add(field.name()); } } } } } ParsedDocument doc = new ParsedDocument(context.uid(), context.version(), context.id(), context.type(), source.routing(), source.timestamp(), source.ttl(), context.docs(), context.analyzer(), context.source(), context.mappingsModified()).parent(source.parent()); // reset the context to free up memory context.reset(null, null, null, null); return doc; }
将整条数据解析成ParsedDocument,解析后的数据才能进行后面的Field解析建立索引。
总结
以上就是Mapping的结构和相关功能概括,Mapper赋予了elasticsearch索引的更强大功能,使得索引和搜索可以支持更多数据类型,灵活性更高,更多关于elasticsearch索引index Mapping关系结构的资料请关注我们其它相关文章!