Selenium模拟用户进行操作网页的最全指南
看到有朋友评论问,用selenium怎么模仿人类行为,去操作网页的页面呢?
我想了想,这确实是一个很大的点,不应该是一段代码能解决的,
就像是,如果让程序模拟人类的行为。例如模拟人类买菜,做饭,吃饭,聊天,蹲坑等
这个过程中最重要的不是结果,不是程序能不能完成这些事,而是做这些事的时候,能不能尽可能地像个人在做的,然后尽力躲过网络警察的审查。
selenium的优势是在于它的休眠机制、可以模拟真实的浏览器指纹,模拟鼠标移动的行为轨迹、处理复杂交互等,可以降低被检测和封锁的风险。
具体的模拟应该要分不同的情况来,以下是一些整理:
1. 配置selenium的浏览器界面
在运行下面的方法前,先把selenium 配置好,尽量多一些selenium的配置,用来绕过监测,下面的简单的写法,严谨一点的话,可以如2、3、4的写法,加上用户代理和禁用自动化特征、防检测的header头写法等:
from selenium import webdriver
from selenium.webdriver.chrome.options import options
options = options()
options.add_argument("--window-size=1920,1080") # 设置浏览器窗口大小
options.add_argument("--disable-blink-features=automationcontrolled") # 禁用自动化控制特征
options.add_argument("user-agent=mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/91.0.4472.124 safari/537.36") # 设置用户代理
driver = webdriver.chrome(options=options)
#加上头的写法
2. 使用代理ip
我们在访问其他网站的时候,使用自己的服务器地址,向对方的网站打个招呼,这个时候会暴露自己的ip地址,就像打电话给别人一样,我们的电话号码也会暴露给了对方。如果频繁地向对方一直打招呼,就容易被对方视作垃圾号码一样拉黑
这就跟被人标记成垃圾号码一样被对方封了,这个是封ip;现在很多人会用虚拟号码去频繁地打电话给别人,哪怕别人拉黑了这个号码,也拉黑不了下一个。因为每次打出去的号码都是新的虚拟的号
做代理ip就像是给自己的电脑ip,包装多个虚拟号码一样的外壳, 这样可以保障自己在频繁地访问一个网站的时候,不会轻易被拉黑了。
from selenium import webdriver
proxy = "123.456.789.012:8080" # 示例代理
options = webdriver.chromeoptions()
options.add_argument(f'--proxy-server={proxy}')
driver = webdriver.chrome(options=options)
这个代理ip有付费的网站,也有免费的网站,如果有需要,后期我会再整理各类的网站出来
3. 禁用自动化特征
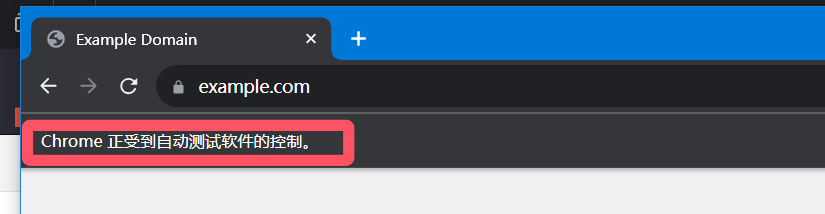
有时候爬取的时候,会显示这样一行字,下面的方法是可以取消这行字的显示,将浏览器包装成非自动化测试的外壳。
options = options()
options.add_experimental_option("excludeswitches", ["enable-automation"])
options.add_experimental_option('useautomationextension', false)
driver = webdriver.chrome(options=options)
4. selenium上构造安全头header
请求头把自己的浏览器信息发送给对方服务器,有点像是给对方服务器递了个名片过去。
单一的header头,也会受到对方服务器的检测,有时候我们也可以有选择地构建安全头内容。
4.1 方法1:通过 add_argument 设置基础 headers(简单但有限)
适用于修改 user-agent 等基础头信息:
from selenium import webdriver
options = webdriver.chromeoptions()
options.add_argument("--user-agent=mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/119.0.0.0 safari/537.36")
options.add_argument("--accept-language=en-us,en;q=0.9")
driver = webdriver.chrome(options=options)
局限性:仅支持部分预定义头(如 user-agent、accept-language),无法添加自定义头(如 authorization)。
4.2 方法2:使用 devtools protocol(推荐,完整控制)
动态的header构建,通过 chrome devtools 的 network.setextrahttpheaders 方法,注入任意 headers:
from selenium import webdriver
from selenium.webdriver.common.by import by
driver = webdriver.chrome()
# 定义自定义 headers
headers = {
"user-agent": "mozilla/5.0 (windows nt 10.0; win64; x64)",
"accept": "text/html,application/xhtml+xml",
"authorization": "bearer token123", # 示例自定义头
"x-custom-header": "myvalue"
}
# 通过 devtools 注入 headers
driver.execute_cdp_cmd("network.enable", {})
driver.execute_cdp_cmd("network.setextrahttpheaders", {"headers": headers})
driver.get("https://example.com")
优点:支持所有自定义 headers,适用于需要 cookie、referer 等复杂场景。
4.3 进阶的header头:使用undetected-chromedriver来构建
反爬会对部分网站会检测 sec- 开头的安全头(如 sec-ch-ua),需用 undetected-chromedriver 规避。
5.模拟鼠标移动与点击
我们在点击网页后,如果有一些交互的按钮,例如要移动到某个位置再点击之类的,我们可能会用find_element 定位元素再进行点击,
但是如果在防检测比较严格的情况下,例如对方浏览器对鼠标进行监控计算,会监测用户是鼠标是不是在移动,如果是上面的方法,这种就没法做到,这时候可以用到actionchains来处理:
from selenium.webdriver.common.action_chains import actionchains
import random
import time
element = driver.find_element_by_id("some-id")
# 模拟人类移动鼠标
actions = actionchains(driver)
actions.move_to_element(element).perform()
# 添加随机延迟
time.sleep(random.uniform(0.5, 2.5))
# 模拟人类点击(先移动再点击)
actions.click(element).perform()
但是这种方法会一直占用鼠标的使用的,导致我们爬虫之余没法做其他的事情,处于下策,能不用就尽量不用。
6.模拟鼠标滚动的行为
我们在浏览页面的时候,会有滚动鼠标,看下滑的页面,下滑不是一直滑,而是会停一会,再下拉页面一会
即模拟人的人眼在看到页面后的反应,脑子会对眼球的视觉信息做处理,停留思考一会,这时候会有一个间隔的空隙,
这个空隙可以用随机休眠的方法处理:
import random
# 随机滚动页面
scroll_pause_time = random.uniform(0.5, 1.5)
scroll_height = random.randint(200, 800)
for i in range(random.randint(1, 5)):
driver.execute_script(f"window.scrollby(0, {scroll_height});") #用js模拟滚动鼠标的操作
time.sleep(scroll_pause_time) #间隔休眠的时间
7.模拟浏览页面时,停留一些时间
人在浏览网页的时候,不会一直都无停留地一直切换不同的浏览器的网页,我们在不同的网页间切换,要随机增加一些睡眠,原理同上
import random # 不同页面间的随机等待 wait_times = [1, 1.5, 2, 2.5, 3, 4, 5] driver.get(url_1) time.sleep(random.choice(wait_times)) driver.get(url_2) time.sleep(random.choice(wait_times))
8. 模拟在输入框里输入文字的行为
在模拟人在手敲键盘的时候,模拟一个字一个字得打出来,
这个一字一顿,得用到字与字输出的休眠
这种方法的实现是for循环里打出一堆字的时候,在每个字之间增加随机的休眠,如:
from selenium.webdriver.common.keys import keys
text_field = driver.find_element_by_id("search-box")
# 模拟人类打字速度
text_to_type = "example search query"
for char in text_to_type:
text_field.send_keys(char)
time.sleep(random.uniform(0.1, 0.3)) # 随机输入间隔
# 随机等待后按回车
time.sleep(random.uniform(0.5, 1.5))
text_field.send_keys(keys.return)
9. 模拟人类错误与纠正
我们在打字的时候,有时候会写错字,需要删除内容,然后再重新输入
这个模拟写错又纠错的过程,如下:
# 模拟输入错误并纠正
search_box = driver.find_element_by_name("q")
# 故意输入错误
search_box.send_keys("mistake")
time.sleep(random.uniform(0.5, 1.5))
# 模拟退格删除
for _ in range(3):
search_box.send_keys(keys.back_space)
time.sleep(random.uniform(0.1, 0.3))
# 输入正确内容
search_box.send_keys("correct term")
10. 标签页与窗口行为模拟
如果爬取时间比较长的话,我们一直在一个标签页的窗口上一直操作,也不太合理,要时不时打开新的标签页,进行处理
下面的方法是用概率来限制打开标签页的次数:
# 随机打开新标签页
if random.random() > 0.7: # 30%概率打开新标签
driver.execute_script("window.open('https://example.com');")
time.sleep(random.uniform(1, 3))
# 切换回原标签页
driver.switch_to.window(driver.window_handles[0])
time.sleep(random.uniform(0.5, 1.5))
11. 操作顺序随机化
一些可以点击的元素,不要按顺序一个个顺着去点,要调换顺序,随机去点,例如:
写法:
actions = [
lambda: driver.execute_script("window.scrollby(0, 200);"),
lambda: driver.find_element_by_link_text("about").click(),
lambda: driver.back(),
lambda: time.sleep(random.uniform(1, 2))
]
random.shuffle(actions)
for action in actions[:random.randint(1, 3)]:
action()
time.sleep(random.uniform(0.5, 1.5))
12. 下载文件时,模拟网络条件限定速度
下载一些文件的时候,模拟网络的状态,设置下载的速度,不要太快,或者太频繁下载:
from selenium.webdriver.common.desired_capabilities import desiredcapabilities
caps = desiredcapabilities.chrome
caps['goog:loggingprefs'] = {'performance': 'all'}
caps['networkconditions'] = {
'offline': false,
'latency': 100, # 额外延迟(ms)
'download_throughput': 500 * 1024, # 最大下载速度
'upload_throughput': 500 * 1024 # 最大上传速度
}
driver = webdriver.chrome(desired_capabilities=caps)
到此这篇关于selenium模拟用户进行操作网页的最全指南的文章就介绍到这了,更多相关selenium操作网页内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!