python基础篇之:网络爬虫及python实现网络爬虫
一、什么是网络爬虫
随着大数据与人工智能时代的来临,有效地获取和利用信息成为了一项挑战,从而使网络爬虫越来越受到人们的重视与青睐。
网络爬虫,又称为网络机器人或者网页蜘蛛,是一种按照一定规则自动抓取万维网信息的程序或者脚本。网络爬虫大致可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫以及深层网络爬虫等类型。在实际的网络爬虫系统中,通常是结合了几种爬虫技术实现的。

二、网络爬虫应用
1、通用型爬虫
通用型网络爬虫的典型的应用便是我们熟知的搜索引擎,例如百度、谷歌等,但是该类爬虫存在许多弊端。例如,不同的用户对于检索具有不同的需求和目的,而通用搜索引擎返回的结果包含大量无用的网页;再如,由于图片、音频、视频等多媒体数据的不断涌现,通用搜索引擎不能很好地发现和获取信息等等。
2、聚焦爬虫
为了解决以上弊端,聚焦爬虫应运而生,它根据既定的抓取目标对万维网上的相关网页与链接进行有选择的访问,并获取所需信息。
3、增量式爬虫
增量式爬虫是指对已下载网页采取增量式更新,对于没有变化的网页并不重新下载,大大减少了下载量,也减少了时间与空间的浪费,但同时增加了算法和实现的复杂度。
对于Web页面,其存在方式有表层和深层网页,深层网页不能仅仅通过静态网页链接获取,其数据隐藏在表单之后,只有通过用户提交相关必要关键词才能获取,因此需要深层网络爬虫技术的支持。
三、网络爬虫基本工作流程
以通用网络爬虫为例,网络爬虫基本工作流程为:选取种子URL(可以由用户人为指定,也可以由用户指定的某几个初始爬取网页决定);将其放入待抓取URL队列;读取URL;解析DNS;得到主机IP;下载对应网页;存储网页;分析已抓取的URL,并从中分析出其他链接的URL,同时比较去重;将去重后的URL再次放入到待抓取URL队列,进入下一次循环。通用网络爬虫结构流程如图下图所示。
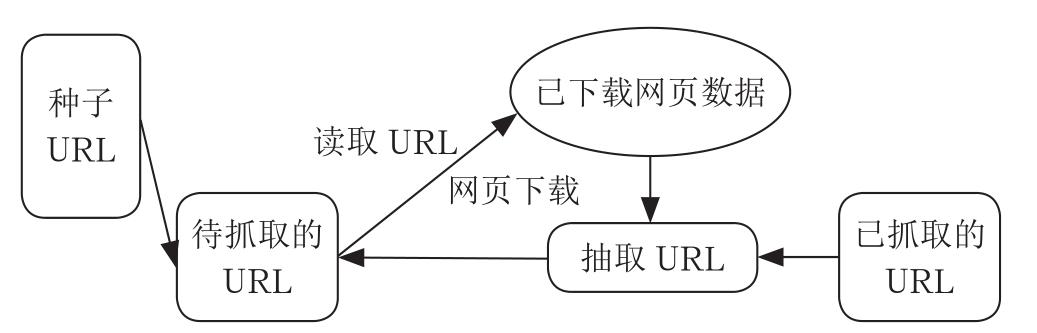
通用网络爬虫结构流程图
四、python实现网络爬虫
开发网络爬虫的语言有很多,常见的开发语言有Python、Java、PHP、Node.JS、C++以及Go等语言。本文主要阐述基于Python的网络爬虫,Python语言的特点是简单易学、代码简洁并且框架非常丰富,同时Python之所以强大并能够在网络爬虫中占据一席之地,与其强大的第三方库是分不开的。Python为爬虫提供了丰富的第三方库,其中较为常用的Python中爬虫三大库,即Requests库、Beautiful Soup库以及lxml库。根据实际需求可选用相应爬虫库进行实现。Python实现网络爬虫的基本流程如下图所示。

python实现网络爬虫基本流程
主要流程可分为四步:
(1)发送请求:即发送一个Request;
(2)获取相应内容:即得到Response;
(3)解析内容:对于HTML数据使用re模块或第三方库等;
(4)保存数据:数据库或者文件中保存。
在网络爬虫的爬取过程中,比如聚焦网络爬虫中,爬取网页的顺序尤其重要,而爬取的顺序一般由爬取策略来决定。爬行策略有很多种,包括广度优先爬行策略、深度优先爬行策略、大站优先爬行策略、反链爬行策略(反向链接的网页数越多的优先爬取)以及OPIC策略、Partial策略和PageRank策略等爬行策略。

五、共享识刻
如果你处于想学python或者正在学习python,python的教程肯定是少不了的。说不定你学了可能是两年前人家就学过的内容,在这小编分享一波2020最新的python全套教程,共计约400集,另附60本PDF电子书籍免费分享给大家!
能用到这些资料的可以关注下小编,并在后台私信小编:“python”即可领取。希望能帮助到各位。也希望每位用心学习python的朋友,日后都能成为一名合格的python程序员。
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24