正确使用索引和Explain工具,MySQL性能提升

可以有多种不同层次的技术提高应用程序性能,但是通常我们首先关注的是数据库方面——这是最常见的性能瓶颈。数据库的性能可以改善吗?我们如何衡量,到底什么需要性能改进?
一个非常简单但非常有用的工具是查询分析工具(query profiling)。启用分析是获得运行查询的更准确时间的一种简单方法。
这可以分两步来说。首先,我们必须启用分析工具。然后,我们调用执行Sql语句,使用查询分析工具来实际获取查询运行时间。
假设我们的数据库中已经有以下插入数据(假设User 1 和 Gallery 1 已经创建好了):
INSERT INTO `homestead`.`images` (`id`, `gallery_id`, `original_filename`, `filename`, `description`)
VALUES(1, 1, 'me. jpg ', 'me.jpg', 'A photo of me walking down the street'),
(2, 1, 'dog.jpg', 'dog.jpg', 'A photo of my dog on the street'),
(3, 1, 'cat.jpg', 'cat.jpg', 'A photo of my cat walking down the street'),
(4, 1, 'purr.jpg', 'purr.jpg', 'A photo of my cat purring');
虽然,这些数据处理起来很简单,但是让我们用它来做一个示例。让我们考虑执行以下查询:
SELECT * FROM `homestead`.`images` AS iWHERE i.description LIKE '%street%';
这个查询是一个很好的例子,如果我们得到大量的照片记录,这个查询将来可能会出现问题。
为了在此查询中获得准确的运行时间,我们将使用以下SQL:
set profiling = 1; SELECT * FROM `homestead`.`images` AS iWHERE i.description LIKE '%street%'; show profiles;
查询结果如下所示:
Query_IdDurationQuery 10.00016950SHOW WARNINGS20.00039200SELECT * FROM homestead.images AS i nWHERE i.description LIKE ’%street%’nLIMIT 0, 100030.00037600SHOW KEYS FROM homestead.images40.00034625SHOW DATABASES LIKE ’homestead50.00027600SHOW TABLES FROM homestead LIKE ’images’60.00024950SELECT * FROM homestead.images WHERE 0=170.00104300SHOW FULL COLUMNS FROM homestead.images LIKE ’id’
正如我们所看到的,show profiles命令不仅记录原始查询花费的时间,而且还可以查看所做的所有其他查询耗费的时间。
这样我们就可以精确地进行分析查询。
但我们如何才能真正改善SQL执行性能呢?
我们可以依赖我们自己的SQL知识和即兴发挥,也可以依赖 MySQL EXPLAIN 命令,根据实际执行情况数据来改进查询性能。
Explain用于获取查询执行计划,或者MySQL如何执行查询。它与SELECT、DELETE、INSERT、REPLACE和UPDATE语句一起工作,并显示来自优化器的关于语句执行计划的信息。
官方文件很好地描述了explain是如何帮助我们的:
在EXPLAIN的帮助下,您可以看到应该向表中添加 索引 ,以便通过使用索引查找行来更快地执行语句。您还可以使用EXPLAIN检查优化器是否以最佳顺序连接表。
为了举例说明explain的用法,我们将使用UserManager.php文件中的sql查询,通过指定的电子邮件来寻找用户:
SELECT * FROM `homestead`.` users ` WHERE email = 'claudio.ribeiro@examplemail.com';
执行结果如下表:

这些结果乍一看不容易理解,让我们仔细挨个看一下:
id:这只是SELECT中每个查询的顺序标识符。
select_type:
SELECT查询的类型。这个字段可以取很多不同的值,所以我们将重点关注最重要的值:
SIMPLE: 没有子查询或联合的简单查询
PRIMARY: select在连接的最外层查询中
DERIVED: :select是from中的子查询的一部分
SUBQUERY: 子查询中的第一个选择
UNION: select是UNION的第二个或以后的语句。
可以在这里找到可以出现在select_type字段中的完整值列表(#explain_select_type)。
- table: row行引用的表。.
- type: 这个字段是MySQL连接使用的表的方式。这可能是explain输出中最重要的字段。它可以指示缺失的索引,还可以显示应该如何重写查询。该字段的可能值如下(从最佳类型到最差类型排序):
- system:该表有0行或一行。
- const:该表只有一个被索引的匹配行。这是最快的连接类型。
- eq_ref:该索引的所有部分都被连接使用,索引是PRIMARY_KEY或UNIQUE NOT NULL。
- ref:索引列的所有匹配行都为来自前一个表的每个行组合读取。与=或<=>操作符相比,这种类型的连接通常用于索引列。
- fulltext:联接使用表 全文索引 。
- ref_or_null:这与ref相同,但也包含列中值为空的行。
- index_merge: join使用一个索引列表来生成结果集。explain的键列将包含所使用的键。
- unique_subquery: IN子查询只返回表中的一个结果,并使用主键。
- range:索引用于查找特定范围内的匹配行。
- index:扫描整个索引以找到匹配的行。
- all:扫描整个表以查找连接的匹配行。这是最糟糕的连接类型,通常表明表上缺少适当的索引。
- possible_keys:显示MySQL可以使用的键,以便从表中查找行。这些键可以在实践中使用,也可以不使用。
- key:指示MySQL使用的实际索引。MySQL总是寻找可以用于查询的最优密钥。在连接多个表时,它可能会发现一些其他的键,这些键不可能被列在可能的键中,但是它们是最优的。
- key_len:指示查询优化器选择使用的索引的长度。
- ref:显示与键列中命名的索引相比较的列或常量。
- row:列出为生成输出而检查的记录的数量。这是一个非常重要的指标;检查的记录越少越好。
- extra:包含额外的信息。值,如在此列中使用filesort或使用临时性值,可能表示查询麻烦。
Explain输出格式的完整文档可以在MySQL官方页面找到。(
接下来回到我们刚才创建简单查询:它是一种简单的select类型,具有const类型的连接。这是我们能得到的最好的查询情况。但是当我们需要更大更复杂的查询时,会发生什么呢?
回到我们的应用程序模式,我们可能想要获得所有的图库图像。我们也可能希望只有描述中包含“cat”一词的照片,让我们看一下查询:
SELECT gal.name, gal.description, img.filename, img.description FROM `homestead`.`users` AS users LEFT JOIN `homestead`.`galleries` AS gal ON users.id = gal.user_id LEFT JOIN `homestead`.`images` AS img on img.gallery_id = gal.id WHERE img.description LIKE '%dog%';
在这个更复杂的情况下,使用Explain,我们可以有更多的信息来进行分析:
EXPLAIN SELECT gal.name, gal.description, img.filename, img.description FROM `homestead`.`users` AS users LEFT JOIN `homestead`.`galleries` AS gal ON users.id = gal.user_id LEFT JOIN `homestead`.`images` AS img on img.gallery_id = gal.id WHERE img.description LIKE '%dog%';
结果如下:
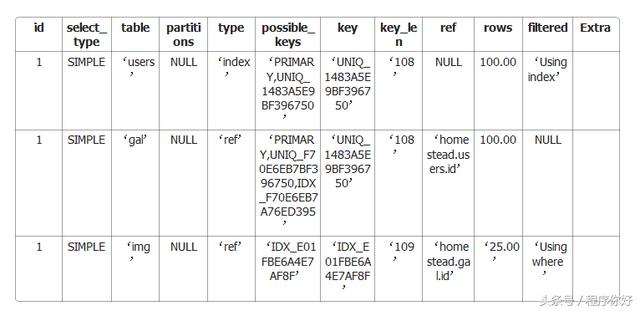
让我们仔细看看,看看我们能在上面的查询中改进什么。
正如我们前面看到的,我们首先应该查看的主要列是Type类型列和Row行列。目标应该在type列中获得更好的值,并尽可能减少行列的值。
第一个查询的结果是index,这根本不是一个好结果。这意味着我们可以改进它。
接下来分析我们的查询语句,有两种方式来解决问题。首先,User表没有被使用。我们要么扩展查询以确保我们针对的是目标用户,要么完全删除查询的用户部分。它给我们的整体性能增加了复杂性和时间。
SELECT gal.name, gal.description, img.filename, img.description FROM `homestead`.`galleries` AS gal LEFT JOIN `homestead`.`images` AS img on img.gallery_id = gal.id WHERE img.description LIKE '%dog%';
现在我们得到了完全相同的结果。让我们来看一下explain分析表格:

我们的type变成了ALL。虽然所有连接都可能是最糟糕的连接类型,但也有时候这是没办法的选择。根据我们的要求,我们想要所有的画廊图片,所以我们需要浏览整个画廊的桌子。虽然索引在试图查找表上的特定信息时非常有用,但是当我们需要表中的所有信息时,索引没办法提高查询性能。当我们遇到这种情况时,我们必须采用另外的方法,比如缓存。
我们可以做的最后一个改进是,在我们处理LIKE时,向description字段添加一个全文索引。通过这种方式,我们可以将LIKE改为match()并改进性能。更多全文索引可以在这里找到()。
我们还必须研究两个非常有趣的情况:应用程序中newest(最新的)和related(相关的)的功能。
EXPLAIN SELECT * FROM `homestead`.`galleries` AS gal LEFT JOIN `homestead`.`users` AS u ON u.id = gal.user_id WHERE u.id = 1ORDER BY gal.created_at DESCLIMIT 5;
相关的related 项.
EXPLAIN SELECT * FROM `homestead`.`galleries` AS galORDER BY gal.created_at DESCLIMIT 5;
最新的数据项.
乍一看,这些查询应该非常迅速,因为它们正在使用LIMIT。这就是大多数查询使用LIMIT的情况。不幸的是,对于我们和我们的应用程序,这些查询也使用ORDER BY。因为我们需要在LIMIT查询之前对所有结果进行排序,所以我们失去了使用LIMIT的优势。
既然我们知道按顺序排列是很棘手的,那就让我们使用工具执行查询分析一下。
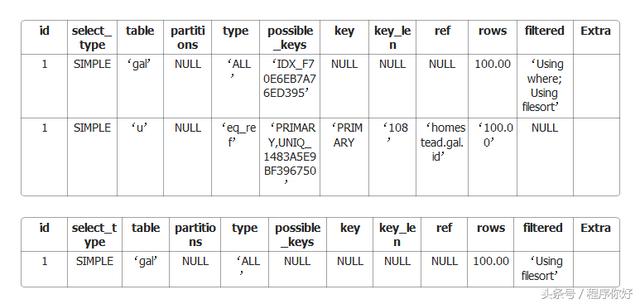
如我们所见,我们有最糟糕的join类型:ALL用于我们的两个查询。
从历史上看,MySQL的实现Order By排序,尤其是加上LIMIT,常常是导致MySQL性能问题的原因。这种组合也用于大多数具有大型数据集的交互式应用程序。像新注册用户和顶级标签这样的功能通常使用这种组合。
因为这是一个常见的问题,所以我们应该应用一些常见的解决方案来解决性能问题。
- 确保我们在使用索引 。在我们的例子中,created_at是一个很好的候选者,因为它是我们所订购的字段。这样,我们就可以执行ORDER BY和LIMIT,而无需扫描和排序整个结果集。
- 表中的第一列进行Order By排序。通常,如果ORDER BY是从表中按字段进行的,而不是联接顺序中的第一个,则不能使用索引。
- 不要通过表达式。表达式和函数不允许使用索引。
- 注意一个大的极限值( LIMIT value )。大的极限值会强制排序,以排序更大的行数。这会影响性能。
这些是我们在既有限制又有秩序的情况下应该采取的一些措施,以尽量减少性能问题。
结论
正如我们所看到的,explain对于及早发现查询中的问题非常有用。有很多问题我们只会在应用程序在生产时,并且有大量的数据或大量的访问者访问数据库的情况才会注意到。如果可以在使用explain时及早发现这些问题,那么将来出现性能问题的可能性就会小得多。
我们的应用程序拥有它所需要的所有索引,而且速度非常快,但是我们现在知道,每当我们需要检查性能提升时,我们总是可以使用解释和索引。
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24