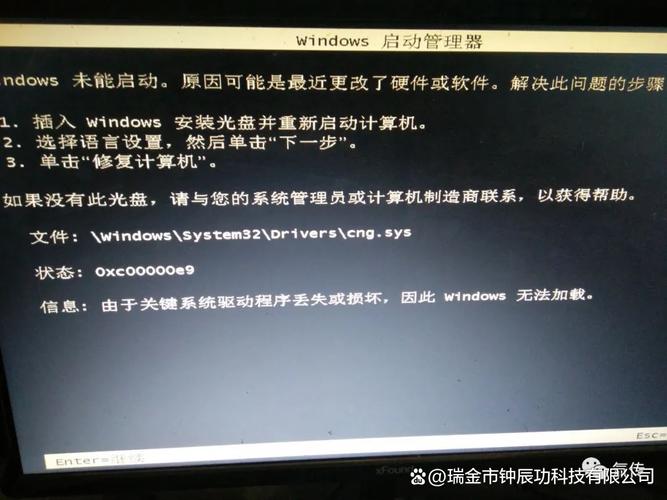
为什么CRT报错信息显示为乱码?
在日常使用计算机或管理服务器的过程中,许多用户可能都曾遇到过这样的情况:弹出一个错误提示框,内容却是一堆无法理解的乱码字符,这种情况在涉及安全证书(如CRT文件)相关操作时尤为常见,面对这类问题,用户往往感到困惑,甚至因无法定位问题根源而产生焦虑,本文旨在解析这一现象的原因,并提供清晰的解决思路。
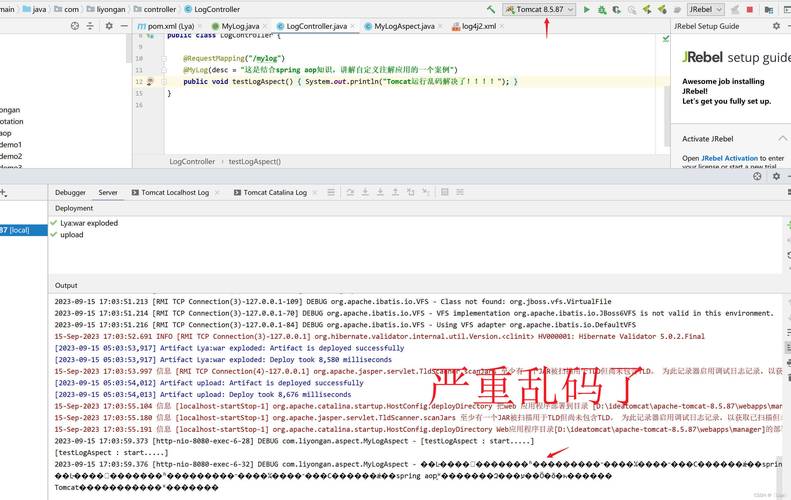
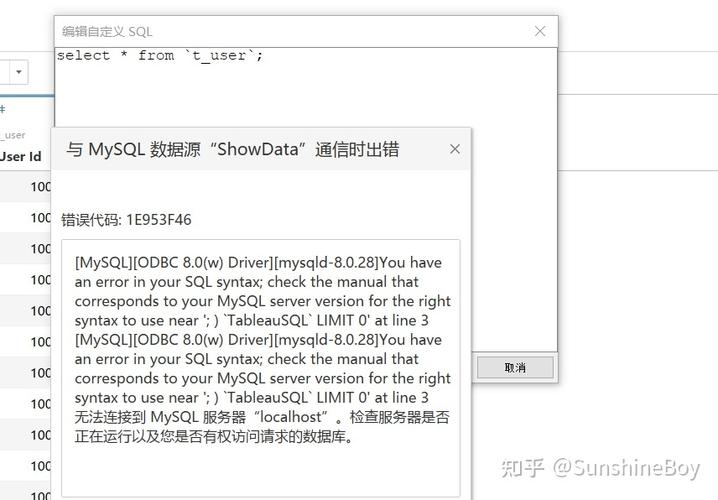
出现CRT报错信息乱码,通常并非系统或软件本身的核心故障,而是由环境配置或信息呈现环节的偏差导致,最常见的原因之一是系统或应用程序的字符编码设置不匹配,计算机在处理文本信息时,依赖于特定的字符编码标准,如UTF-8、GBK、ISO-8859-1等,当程序试图显示错误信息时,如果其预期的编码格式与系统当前使用的编码格式不一致,就会导致字符解析错误,从而呈现为乱码。
一个设计为在UTF-8环境下输出错误信息的程序,若运行在默认编码为GBK的系统终端中,就可能出现中文字符显示为乱码的情况,反之亦然,这种编码冲突在跨平台操作或使用不同语言版本的系统时更容易发生。
另一个可能的原因是本地化资源文件缺失或损坏,一些软件会将错误信息存储在特定的语言资源文件中,如果该文件丢失,或由于更新不完全、安装不完整等原因导致损坏,程序可能无法正确调用对应的文字描述,转而输出原始的内存数据或错误代码,这些内容对用户而言就如同乱码一般。
终端模拟器或显示设置的问题也不容忽视,部分远程连接工具(如SSH客户端)或系统自带的命令行终端,如果其字体设置不支持错误信息所使用的字符集,或者终端本身的编码配置有误,同样会将清晰的报错信息渲染成无法识别的符号。
如何有效地应对和解决这一问题呢?解决思路应当遵循从外到内、由易到难的原则。
尝试检查并统一字符编码环境,可以手动设置系统或终端的编码格式,在Windows的命令提示符(cmd)中,可以通过输入命令chcp 65001来将当前代码页设置为UTF-8,在Linux或macOS的终端中,可通过检查并设置LANG或LC_ALL环境变量为zh_CN.UTF-8或en_US.UTF-8等来确保使用统一的UTF-8编码,确认使用的终端软件(如PuTTY、SecureCRT、iTerm2等)的编码设置已正确配置为与系统及远程主机一致。
验证软件的完整性,如果怀疑是程序本身的本地化文件出了问题,可以尝试重新安装该软件,或修复安装,以确保所有语言包和资源文件完整且未损坏,对于开源软件,有时还可以在官方社区或文档中查询到特定错误代码的含义,从而绕过乱码直接理解问题根源。

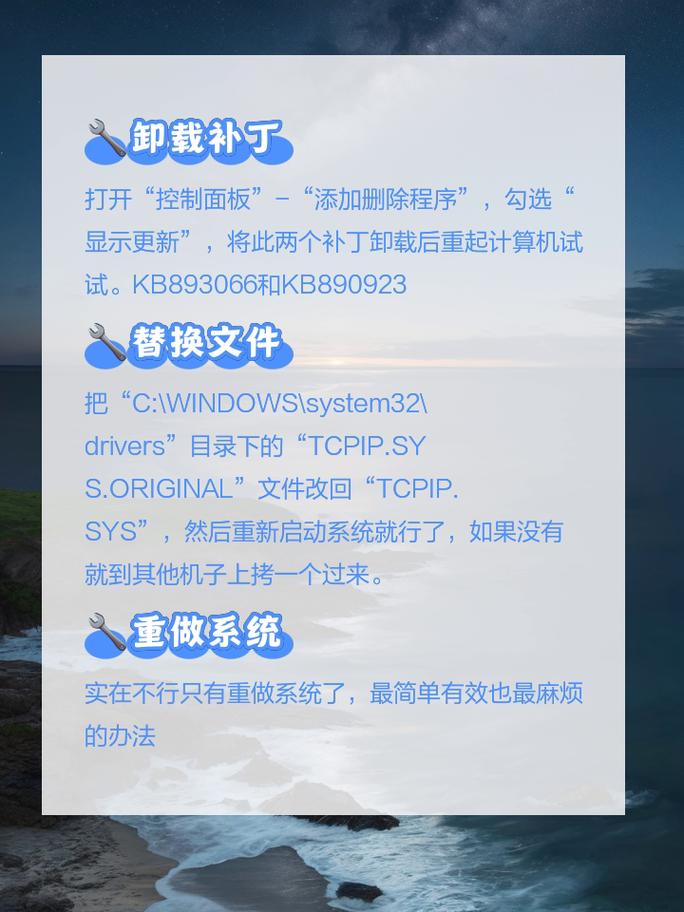
关注系统区域和语言设置,进入操作系统的控制面板或设置中心,检查“区域与语言”、“管理非Unicode程序的语言”等选项,有时,将非Unicode程序使用的语言设置为与系统一致或调整为中文(简体,中国),可以解决部分传统软件或特定环境下的乱码问题。
如果上述方法均无效,问题可能更深层,考虑查看系统日志或应用程序的日志文件,日志中的记录通常是纯文本,可能以正确的编码格式记载了错误的原始信息,这能为诊断问题提供关键线索,在Windows的事件查看器或Linux的/var/log/目录下,常常隐藏着解决问题的答案。
遇到CRT报错乱码,不必急于将其归咎于复杂的系统故障,多数情况下,它只是一个“信号转换”过程中的小插曲,是不同软件组件间在“对话”时产生了误解,耐心地检查和调整字符编码这一看似基础却至关重要的设置,往往能化繁为简,让清晰的错误信息重现眼前,从而指引我们更快地走向问题解决的终点,技术的价值在于为人服务,而不是制造障碍,理解这一点,就能以更从容的心态应对各种技术挑战。