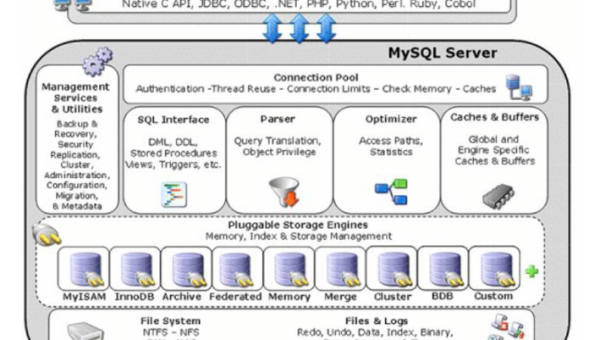
这篇文章将为大家详细讲解有关MySQL怎么联合查询优化机制,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
MySQL 联合查询执行策略。
以一个 UNION 查询为例,MySQL 执行 UNION 查询时,会把他们当做一系列的单个查询语句,然后把对应的结果放入到临时表中,最终再读出来返回。在 MySQL中,每个独立的查询都是一个联合查询,从临时表读取返回结果也一样。
这种情形下,MySQL 的联合查询执行很简单——它将这里的联合查询当做是嵌套循环的联合查询。这意味着 MySQL 会运行一个循环去从数据表读取数据行,然而在运行一个嵌套循环从下一个表读取匹配的数据行。这个过程一直持续,直到找到联合查询中的所有匹配的数据行。然后再根据 SELECT 语句中需要的列去构建返回结果。如下面的查询语句所示:
SELECTtb1.col1,tb2.col2
FROMtb1INNERJOINtb2USING(col3)
WHEREtb1.col1IN(5,6);
实际转换为 MySQL可能执行的伪代码是下面这样的:
outer_iter=iteratorovertb1wherecol1IN(5,6);
outer_row=outer_iter.next;
whileouter_row
inner_iter=iteratorovertb2wherecol3=outer_row.col3;
inner_row=inner_iter.next
whileinner_row
output[outer_row.col1,inner_row.col2];
inner_row=inner_iter.next;
end
outer_row=outer.iter.next;
end
转换为伪代码后如下所示
outer_iter=iteratorovertb1wherecol1IN(5,6);
outer_row=outer_iter.next;
whileouter_row
inner_iter=iteratorovertb2wherecol3=outer_row.col3;
inner_row=inner_iter.next
ifinner_row
whileinner_row
output[outer_row.col1,inner_row.col2];
inner_row=inner_iter.next;
end
else
output[outer_row.col1,NULL];
end
outer_row=outer.iter.next;
end
另一个方式可视化展现查询计划的方式是使用泳道图的形式。下面的图展示了 内连接查询的泳道图。
MySQL 执行的各类查询基本上都是相同的方式。例如,在 FROM 条件里需要先执行的子查询时,也是先将结果放入临时表,然后再把临时表当作普通表后联合来处理。MySQL 执行联合查询时也是使用临时表,然后将右连接查询重写为等价的左连接。简而言之,当前版本的 MySQL 会尽可能把各类查询转成这种方式处理(最新版本 MySQL5.6以后引入了更多的复杂的处理方式)。
当然,并不是所有合法的 SQL 查询语句都可以这么做,有些查询这么做的效果可能很差。
执行计划
MySQL不像其他很多数据库产品,它不会将查询语句产生字节码去执行查询计划。实际上,查询执行计划是一棵指令树,查询执行引擎根据这棵树产生查询结果。最终的查询计划包含了足够多的信息去重构最初的查询。如果在查询语句上执行EXPLAIN EXTENDED(MySQL 8以后不需要加 EXTENDED),然后再执行SHOW WARNINGS,就可以看到重构后的查询。
对于多表查询在概念上可以用树代表。例如,一个4张表的查询可能长得像下面的树一样。这在计算机里称为平衡树,
然而这不是 MySQL 执行查询的方式。如前所述,MySQL 总是从一张数据表开始,然后再从下一张表寻找匹配的数据行。因此,MySQL 的查询计划看起来像下面的左深连接树。
联合查询优化器
MySQL 的查询优化器中最重要的部分是联合查询优化器,由它来决定多表查询执行过程的最优顺序。通常可以通过多种联合查询的次序获取相同的结果。联合查询优化器试图估计这些方案的代价,然后选择最低代价的方案去执行。
下面是一个查询相同结果,但不同次序的联合查询示例。
SELECTfilm.film_id,film.title,film.release_year,actor.actor_id,actor.first_name,actor.last_name
FROMsakila.film
INNERJOINsakila.film_actorUSING(film_id)
INNERJOINsakila.actorUSING(actor_id);
这里面可能会有一些不同的查询方式。比如,MySQL 可以从 film 表开始,使用 film_actor 的film_id 索引去查找对应的 actor_di 值,然后再从 actor 表使用主键找到对应的 actor 数据行。而 Oracle 用户可能会表述为:“film 表是 film_actor 的驱动表,而 film_actor 是 actor 表的驱动表”。而使用 Explain 解析的结果如下:
********1.row********
id:1
select_type:SIMPLE
table:actor
type:ALL
possible_keys:PRIMARY
key:NULL
key_len:NULL
ref:NULL
rows:200
Extra:
********2.row********
id:1
select_type:SIMPLE
table:film_actor
type:ref
possible_keys:PRIMARY,idx_fk_film_id
key:PRIMARY
key_len:2
ref:sakila.film.film_id
rows:1
Extra:USINGindex
********3.row********
id:1
select_type:SIMPLE
table:film
type:eq_ref
possible_keys:PRIMARY
key:PRIMARY
key_len:2
ref:sakila.film_actor.film_id
rows:1
Extra:
这个执行计划与我们猜想的有很大不同。MySQL 首先从 actor 表开始,然后次序是反向的。这是否真的更有效?我们可以在 EXPLAIN 上加上 STRAIGHT_JOIN 来避免优化:
EXPLAINSELECTSTRAIGHT_JOINfilm.film_id,film.title,film.release_year,actor.actor_id,actor.first_name,actor.last_name
FROMsakila.film
INNERJOINsakila.film_actorUSING(film_id)
INNERJOINsakila.actorUSING(actor_id);
********1.row********
id:1
select_type:SIMPLE
table:film
type:ALL
possible_keys:PRIMARY
key:NULL
key_len:NULL
ref:NULL
rows:951
Extra:
********2.row********
id:1
select_type:SIMPLE
table:film_actor
type:ref
possible_keys:PRIMARY,idx_fk_film_id
key:idx_fk_film_id
key_len:2
ref:sakila.film.film_id
rows:1
Extra:USINGindex
********3.row********
id:1
select_type:SIMPLE
table:actor
type:eq_ref
possible_keys:PRIMARY
key:PRIMARY
key_len:2
ref:sakila.film_actor.actor_id
rows:1
Extra:
这解释了为什么MySQL 为什么需要反序执行查询,这会使得检查的数据行更少。
从这个例子可以看出,MySQL 的联合查询优化器可以通过调整查询表次序降低查询代价。重新排序后的联合查询通常是很有效的优化,通常是几倍性能的提高。如果没有性能提高的话,也可以使用 STRAIGHT_JOIN 来避免重排序,而使用我们自己认为最好的查询方式。这种情况实际遇到的会很少,大部分情况下,联合查询优化器都会比人做得更出色。
联合查询优化器视图以最低完成代价构建一个查询执行树。如果有可能,它会从全部的单表计划开始,检查所有可能的子树组合。不幸的是,一个 N 张表的联合查询会有 N 个阶乘的组合次序数量。这被称之为所有可能的查询计划的搜索空间,这个数量增长非常快。一个10张表的联合索引会有3628800个不同的方式!一旦搜索空间增长到过大,会导致查询的优化十分久,这时候服务端会停止做全量分析,替代以类似贪婪算法的方式完成优化。这个数量通过 optimizer_search_depth 系统变量控制,可以自己修改该参数。
关于“MySQL怎么联合查询优化机制”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。