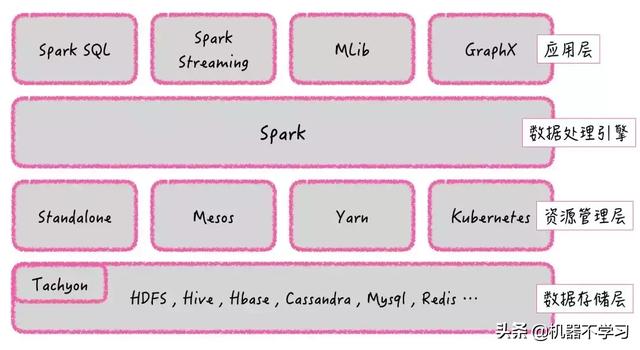
怎么成为大数据Spark高手
发布于 2022-01-14 22:30:49
上一篇:.NET for Apache Spark 1.0有哪些功能 下一篇:生产制造ERP对企业造成有什么影响
目录