如何在CentOS系统上安装Spark?分步指南
CentOS系统下Spark部署指南
Apache Spark作为一款高效的大数据处理框架,凭借其内存计算和分布式处理能力,已成为企业级数据分析的核心工具之一,本文将以CentOS 7/8系统为例,逐步解析Spark的完整安装流程,并提供性能优化建议与常见问题解决方案。
**环境准备
1、系统更新与依赖安装
执行以下命令更新系统并安装基础工具:
sudo yum update -y sudo yum install -y wget curl tar java-1.8.0-openjdk-devel
注意:Spark依赖Java 8或11,推荐使用OpenJDK 8以避免兼容性问题。
2、配置主机名与SSH免密登录(可选)
若需搭建集群环境,需配置各节点的主机名解析:
sudo hostnamectl set-hostname master # 主节点命名为master echo "192.168.1.100 master" | sudo tee -a /etc/hosts
生成SSH密钥并分发至各节点:
ssh-keygen -t rsa ssh-copy-id master # 若为单机测试可跳过此步骤
**Spark安装与配置
1、下载与解压安装包
访问[Apache Spark官网](https://spark.apache.org/downloads.html)获取最新稳定版链接(例如Spark 3.3.1):
wget https://dlcdn.apache.org/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgz tar -xzvf spark-3.3.1-bin-hadoop3.tgz sudo mv spark-3.3.1-bin-hadoop3 /opt/spark
2、环境变量配置
编辑/etc/profile文件,追加以下内容:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
加载配置并验证:
source /etc/profile spark-shell --version # 显示版本号即成功
3、基础参数调优
修改$SPARK_HOME/conf/spark-env.sh:
cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh echo "export SPARK_MASTER_HOST=master" >> $SPARK_HOME/conf/spark-env.sh echo "export SPARK_WORKER_MEMORY=4g" >> $SPARK_HOME/conf/spark-env.sh # 根据内存调整
**运行验证与基础操作
1、启动单机模式
执行以下命令启动Spark独立集群:
$SPARK_HOME/sbin/start-all.sh
通过jps命令查看进程,应包含Master和Worker,访问http://服务器IP:8080可查看Web监控界面。
2、提交测试任务
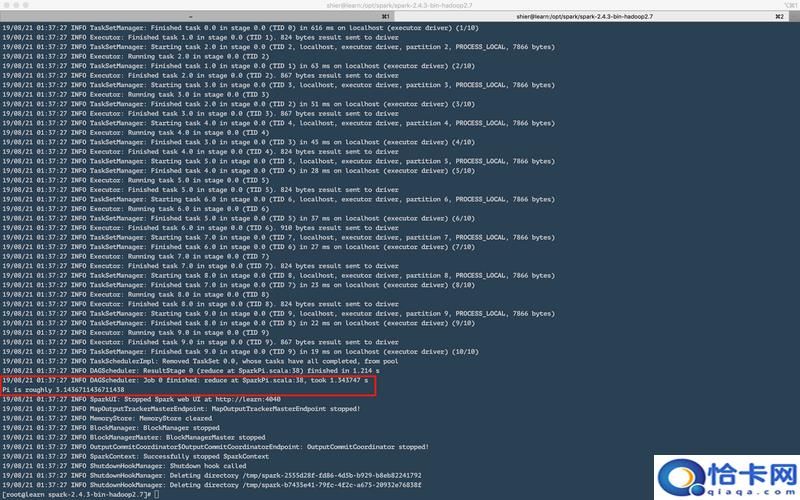
运行内置的Pi计算示例验证集群:
spark-submit --class org.apache.spark.examples.SparkPi \ --master spark://master:7077 \ $SPARK_HOME/examples/jars/spark-examples_2.12-3.3.1.jar 1000
若输出包含Pi is roughly 3.1415则表明运行成功。
**常见问题排查
Java版本冲突
若出现UnsupportedClassVersionError,使用java -version检查版本,并通过alternatives --config java切换至Java 8。
端口占用问题
Spark默认使用8080(Web UI)和7077(Master通信端口),若被占用可修改spark-env.sh中的SPARK_MASTER_WEBUI_PORT参数。
内存不足报错
调整spark-env.sh中的SPARK_WORKER_MEMORY和SPARK_DRIVER_MEMORY值,建议保留至少1GB给系统进程。
**性能优化建议
1、数据本地化配置
在spark-defaults.conf中增加:
spark.locality.wait=3s spark.scheduler.maxRegisteredResourcesWaitingTime=300s
2、启用动态资源分配
添加以下参数实现资源弹性调度:
spark.dynamicAllocation.enabled=true spark.shuffle.service.enabled=true
3、序列化优化
使用Kryo序列化提升性能:
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")从实际运维经验看,Spark的稳定性高度依赖硬件资源配置与参数调优,对于生产环境,建议结合监控工具(如Prometheus+Granafa)实时跟踪Executor内存使用情况,若需处理TB级数据,可进一步研究RDD持久化策略与Shuffle优化技巧。