一文带你解读所有HashMap的面试题
目录
- HashMap
- HashMap 的数据结构
- JDK7 和 JDK8 HashMap哪里不一样
- HashMap是否安全
- HashMap 的扩容机制
关于 HashMap 阿粉相信大家再面试的时候,是非常容易被问到的,为什么呢?因为至少是在 JDK8 出来之后,非常容易被问到关于 HashMap 的知识点,而如果对于没有研究过他的源代码的同学来说,这个可能只是说出一部分来恰卡编程网,比如线程安全,链表+红黑树,以及他的扩容等等,今天阿粉就来把 HashMap 上面大部分会被在面试中问到的内容,做个总结。
HashMap
说到 HashMap 想必大家从脑海中直接复现出了一大堆的面试题,
- HashMap 的数据结构
- JDK7 和 JDK8 HashMap哪里不一样
- HashMap是否安全
- HashMap 的扩容机制
说到这里,我们就来挨着分析一下这个 HashMap 的这写面试题。
HashMap 的数据结构
这个 HashMap 的数据结构,面试官这个问题,属于那种可大可小的,往大了说,那就是需要你把所有的关于 HashMap 中的内容都详细的解释明白,但是如果要是往小了说,那就是介绍一下内部结构,就可以了。
阿粉今天来分析一下这个数据结构了。
HashMap 里面有几个比较重要的参数:
//默认初始容量——必须是2的幂 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//当没有构造函数中指定使用的负载系数 static final float DEFAULT_LOAD_FACTOR = 0.75f;
//扩容的阈值,等于 CAPACITY * LOAD_FACTOR static final int TREEIFY_THRESHOLD = 8;
//降容的阈值 staticfinalintUNTREEIFY_THRESHOLD=6;
//扩容的另外一个参数 staticfinalintMIN_TREEIFY_CAPACITY=64;
参数我们都看到了上述的这些内容了,如果用大白话,怎么去形容这些参数呢?其实这就涉及到这个后面的 JDK8 中的 HashMap 不一样的结构了,
我们也知道 JDK8 中的 HashMap ,如果在横向上是数组的话,那么他的纵向的每一个元素上面,都是一个单项的链表,而这个链表,会根据长度,来进行不通的演化,而这个演化就是扩容成为树结构和降容成为链表结构的关键,而这些关键,都是通过这些参数来进行的定义。
CAPACITY就相当于是 HashMap 中的默认初始容量。
LOAD_FACTOR负载因子
TREEIFY_THRESHOLD树化的阈值,也就是说table的node中的链表长度超过这个阈值的时候,该链表会变成树
UNTREEIFY_THRESHOLD树降级成为链表的阈值(也就是说table的node中的树长度恰卡编程网低于这个阈值的时候,树会变成链表)
MIN_TREEIFY_CAPACITY树化的另一个参数,就是当hashmap中的node的个数大于这个值的时候,hashmap中的有些链表才会变成树。
transient Node<K,V>[] tableHash 表
有些小伙伴在面试的时候,就会说,当 HashMap中的某个 node 链表长度大于 8 的时候,HashMap 中的这个链表就会变成树,实际上不是的,这个还和MIN_TREEIFY_CAPACITY有关系,也就是说整个 HashMap 的 node 数量大于64,node 的链表长度大于 8 才会变成树。
JDK7 和 JDK8 HashMap哪里不一样
JDK7我们大家也都知道,如果按照横向是数组,那么他的纵向每个元素上面,都是一个单向的链表,而横向上,每一个实体,就相当于是一个 Entry 的实例。
而这每一个 Entry 中都包含了四个属性,
- key
- value
- hash值
- 用于单项列表的next
就像下图这个样子
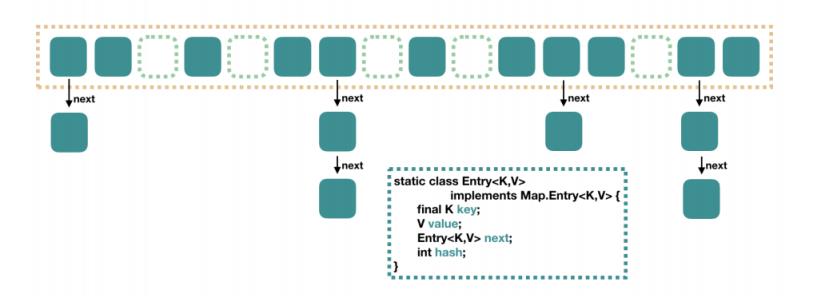
JDK7
所以 JDK7 的 HashMap 的数据结构就是数组+链表的形式构成
而 JDK8 就不一样了,因为他们的内部很巧妙的给增加了红黑树,如下图
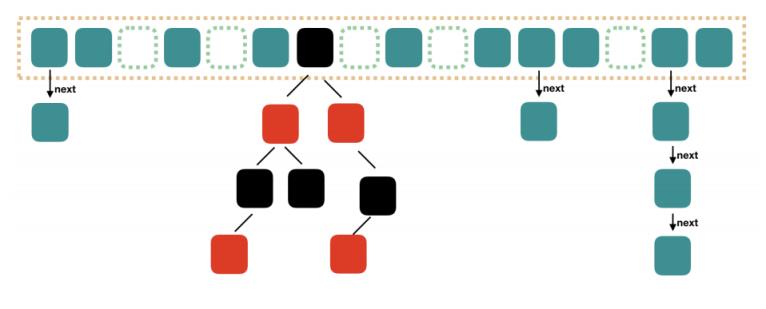
JDK8
所以 JDK8 的 HashMap 的数据结构就是数组+链表+红黑树的形式构成了。
HashMap是否安全
一说这个,肯定都是非常基础的面试题,都知道 HashMap 是属于那种线程不安全的类,为什么不安全,他不安全到底会提现在哪个地方,难道面试的时候,你就只会说他的内部没有被 synchronize 关键字控制么?
所以,说起 HashMap 的不安全,那么就得从 put 和 get 方法说起了。
这个直接先看内部实现,我们先来看 put 方法,然后去分析这个 put 方法,
publicVput(Kkey,Vvalue){
returnputVal(hash(key),key,value,false,true);
}
finalVputVal(inthash,Kkey,Vvalue,booleanonlyIfAbsent,
booleanevict){
Node<K,V>[]tab;Node<K,V>pythonp;intn,i;
//在这里先进行Hash表的初始化
if((tab=table)==null||(n=tab.length)==python0)
n=(tab=resize()).length;
//通过Hash值计算在Hash表中的位置,并将这个位置的元素赋值给P如果等于空的话创建一个新的node
if((p=tab[i=(n-1)&hash])==null)
tab[i]=newNode(hash,key,value,null);
else{
Node<K,V>e;Kk;
//Hash表的当前的index已经存在了元素,向这个元素后追加链表
if(p.hash==hash&&
((k=p.key)==key||(key!=null&&key.equals(k))))
e=p;
elseif(pinstanceofTreeNode)
e=((TreeNode<K,V>)p).putTreeVal(this,tab,hash,key,value);
else{
for(intbinCount=0;;++binCount){
//新建接点,并且追加到列表
if((e=p.next)==null){
p.next=newNode(hash,key,value,null);
if(binCount>=TREEIFY_THRESHOLD-1)//-1for1st
treeifyBin(tab,hash);
break;
}
if(e.hash==hash&&
((k=e.key)==key||(key!=null&&key.equals(k))))
break;
p=e;
}
}
if(e!=null){//existingmappingandroidforkey
VoldValue=e.value;
if(!onlyIfAbsent||oldValue==null)
e.value=value;
afterNodeAccess(e);
returnoldValue;
}
}
++modCount;
if(++size>threshold)
resize();
afterNodeInsertion(evict);
returnnull;
}
看到源码之后,我们猜想一下都会有哪些地方会出问题呢?比如,这时候如果有两个线程同时去执行 put
一个线程 A 执行put("1","A");
一个线程 B 执行put("2","B");
如果这个时候线程 A 和 B 都执行了if ((p = tab[i = (n - 1) & hash]) == null)但是,如果这个时候线程 A 先执行了tab[i] = newNode(hash, key, value, null);这时候,内部是没啥问题的,已经放进去了,
这时候如果线程 B 去执行tab[i] = newNode(hash, key, value, null);就会导致 A 线程中的 key 为 1 的元素 A 丢失。直接被线程 B 进行了覆盖,这也是为什么会有一些人说, JDK7 中是对扩容时会造成环形链或数据丢失,而在 JDK8 中是会会发生数据覆盖的情况。
就会出现 null 的问题,这个问题,不论是 JDK7 还是 JDK8 全都有这个问题,如果面试的时候,能够从这个地方分析一下的,至少这个线程不安全,你确实是自己去研究了一下,所以这就可以完美的解释了,HashMap 的线程不安全的问题了。
HashMap 的扩容机制
我们在上面也都列举了一下 HashMap 的一些关键参数,接下来,就来分析他的扩容是怎么实现的 ,
publicHashMap(intinitialCapacity,floatloadFactor){
if(initialCapacity<0)
thrownewIllegalArgumentException("Illegalinitialcapacity:"+
initialCapacity);
if(initialCapacity>MAXIMUM_CAPACITY)
initialCapacity=MAXIMUM_CAPACITY;
if(loadFactor<=0||Float.isNaN(loadFactor))
thrownewIllegalArgumentException("Illegalloadfactor:"+
loadFactor);
this.loadFactor=loadFactor;
this.threshold=tableSizeFor(initialCapacity);
}
这段代码,写的看起来非常的舒服,指定了初始容量和加载因子,下一次需要扩容的容量threshold值由tableSizeFor方法得出
staticfinalinttableSizeFor(intcap){
intn=cap-1;
//>>>:无符号右移。无论是正数还是负数,高位通通补0。
n|=n>>>1;
n|=n>>>2;
n|=n>>>4;
n|=n>>>8;
n|=n>>>16;
return(n<0)?1:(n>=MAXIMUM_CAPACITY)?MAXIMUM_CAPACITY:n+1;
}
而tableSizeFor这个方法是用于计算出大于等于 cap 值的最大的2的幂值,而后续 HashMap 需要扩容时,每次 table 数组长度都扩展为原来的两倍,所以,table 数组长度总是为2的幂值。
为什么用位移运算,不直接使用.pow的方法, 这个东西,很明显, 位运算这种方式,效率可比.pow的效率要高很多,接下来就是正儿八经的扩容方法了。
finalNode<K,V>[]resize(){
Node<K,V>[]oldTab=table;
intoldCap=(oldTab==null)?0:oldTab.length;//旧容量
intoldThr=threshold;//旧的需要扩容的阈值
intnewCap,newThr=0;
if(oldCap>0){//如果不是第一次扩容
if(oldCap>=MAXIMUM_CAPACITY){
threshold=Integer.MAX_VALUE;//如果容量大于最大值,将阈值设为最大值,这样不会发生下次扩容
returnoldTab;
}
//扩容容量为上一次容量的两倍
elseif((newCap=oldCap<<1)<MAXIMUM_CAPACITY&&
oldCap>=DEFAULT_INITIAL_CAPACITY)
newThr=oldThr<<1;//下次扩容阈值等于本次扩容阈值*2,因为扩容会扩为原来容量的两倍,所以依然满足newThr=newCap*loadFactor
}
elseif(oldThr>0)//第一次扩容,并且用户指定了初始容量
newCap=oldThr;//扩展的容量为阈值
else{//第一次扩容,并且初始容量和加载因子使用的默认值
newCap=DEFAULT_INITIAL_CAPACITY;
newThr=(int)(DEFAULT_LOAD_FACTOR*DEFAULT_INITIAL_CAPACITY);
}
if(newThr==0){//如果用户指定了初始容量时,并且是第一次扩容
floatft=(float)newCap*loadFactor;
//下次扩容阈值为newCap*loadFactor
newThr=(newCap<MAXIMUM_CAPACITY&&ft<(float)MAXIMUM_CAPACITY?
(int)ft:Integer.MAX_VALUE);
}
threshold=newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[]newTab=(Node<K,V>[])newNode[newCap];//新的数组
table=newTab;
if(oldTab!=null){
for(intj=0;j<oldCap;++j){//将旧数组数据移动到新数组
Node<K,V>e;
if((e=oldTab[j])!=null){
oldTab[j]=null;
if(e.next==null)//如果还不是链表或红黑树,把数据直接移动到新数组中对应位置
newTab[e.hash&(newCap-1)]=e;
elseif(einstanceofTreeNode)//红黑树时的移动数据
((TreeNode<K,V>)e).split(this,newTab,j,oldCap);
else{//链表时移动数据
//原来的key的hash值对应的数组位置可能会发生变化
//因为在做与操作时,现有的数组长度多了两倍,也就是多了一位的与计算
//所以,链表或红黑树中的元素可能在原来位置,或者在原来位置+原来数组长度的位置
Node<K,V>loHead=null,loTail=null;
Node<K,V>hiHead=null,hiTail=null;
Node<K,V>next;
do{
....省略不分
}
}
}
}
returnnewTab;
}
总的来说,扩容就是创建一个新的数组,数组长度为原来的两倍,并将下一次需要扩容的阈值设置为新数组乘以加载因子的大小。
然后将原来数组中的数据移动到新数组中。
如果数组中的元素不是链表和红黑树,那么直接移动到原来旧数组中下标的位置。
否则如果是链表或红黑树,那么其中的数据可能会在原来的位置,或者在原来的位置+原来数组长度的位置,此时将原来的链表或红黑树分为两个链表或红黑树,再把数据移动到相应位置。
到此这篇关于一文带你解读所有HashMap的面试题的文章就介绍到这了,更多相关HashMap面试题内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关文章
本站已关闭游客评论,请登录或者注册后再评论吧~
热门文章

保利为什么叫央企之王(保利是国企还是央企)
2022-07-06

恢复外国人入境时间表(中国取消14天隔离政策了吗)
2021-06-19
香港哪些明星是反港分子(已背叛祖国的明星名单)被国家拉入黑名单明星
2021-04-20

身份造假与销售话术(记者卧底世纪佳缘 揭秘“红娘”)
2021-12-08

PyCharm怎么连接配置mysql数据库?
2021-06-29
如何将cda格式文件转换为mp3格式(cda格式怎么转换成mp3)
2021-12-11