Unicode 和 UTF-8 是什么关系?
绝大多数程序员都听说过 Unicode和UTF-8,但是清楚它们之间关系的人就不多了,关于这个问题,与其苍白的陈述它们的概念,不如举例子说明来得自然。

我前些天碰到一个需求:随机生成几个汉字。原本我便对编码之类的问题发怵,所以完全搞不清楚状况,无奈之下我便上网搜索了一个 PHP 版本的实现:
不过代码里的「 19968 」和「 40869 」是什么玩意?这又牵扯到 Unicode code points,为了更好的说明问题,我们需要把如上十进制转换成十六进制:
shell> php -r 'echo dechex(19968);' 4e00 shell> php -r 'echo dechex(40908);' 9fcc
在 Unicode 官方网站,我们能查到 Unihan Grid Index,其中 CJK Unified Ideographs 部分包含了大部分的汉字,其 code points 恰恰是从 U+4E00 到 U+9FCC!
单单上面一个例子还不足以说明问题,下面我们挑选一个「博」字深入说明一下:
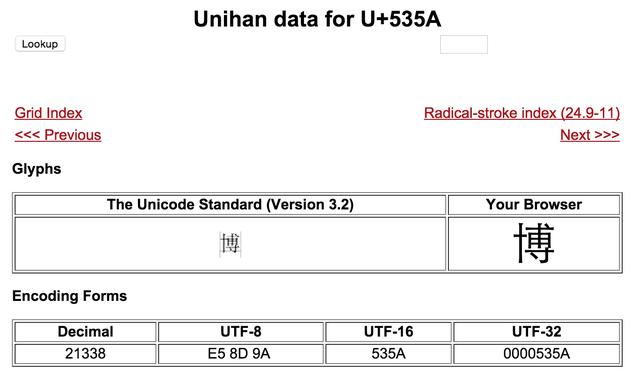
Unicode
因为我们编码是 UTF-8,所以就先看看「博」字的 UTF-8 编码是什么:
代码看上去有点冗长,实际上利用 pack/unpack 函数可以很简单的实现类似的逻辑:
shell> php -r 'var_dump(unpack("H6", "博"));'
array(1) {
["codes"]=>
string(6) "e58d9a"
}
于是乎「博」字的 UTF-8 编码是「e58d9a」,再看怎么得到 unicode code point:
shell> php -r 'echo base_convert("e58d9a", 16, 2);'
11100101 10001101 10011010
如上拿到了「博」字的二进制表示,实际上其 unicode code point 就隐藏在这里。通常汉字用 UTF-8 表示时是三个字节,格式为「 1110XXXX 10XXXXXX 10XXXXXX 」,除掉标志位,把剩余对应位置上的数据抽取出来连接在一起,就得到了 Unicode code point,也就是「 0101 001101 011010 」,剩下的就简单了,把它从二进制转换成十六进制即可:
shell> php -r 'echo base_convert("0101001101011010", 2, 16);'
535a
需要说明的是,如果你仅仅看「博」字,会发现其 Unicode code point 和 UTF-16 是一样的,很容易据此认为它们是等同的概念,实际上这个结论仅仅在双字节(UCS-2)时才是成立的,一旦大于两个字节,就不成立了,有兴趣的可以参考相应的例子。
到底 Unicode 和 UTF-8 是什么关系?一句话:Unicode 是字符集;UTF-8 是编码。
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24