判断元素是否在数组内的几种方法对比
数组是很常用的一个数据结构,而且经常需要判断某个元素是否在数组中,这在 PHP 中有很多种方法,有:
- foreach 循环遍历数据
- in_array()
- array_search()
- isset()
- array_key_exists()
还有其他方法,这里就不说了。我们在网上搜索相关问题基本都是清一色的教我们如何使用 in_array() 函数,好像PHP中判断数组包含某个元素只有这一种方式似的,这次本文就来分析下除 foreach 外其他四种方式的执行效率。
具体四种函数如何使用就不多介绍了,我想看我文章的都不是 LV1 级别的吧,如果不懂请自行查阅 php.net 网站。
测试方法
随机生成一个大数组,然后任取一些元素分别调用上面的几个函数判断是否在生成的大数组内,记录下运行时消耗的最大内存和执行时间。
测试环境
PHP 7.2.34 (cli) (built: Mar 14 2021 18:35:27) ( NTS )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend Technologies
with Zend OPcache v7.2.34, Copyright (c) 1999-2018, by Zend Technologie
测试代码
下面函数创建随机字符的数组:
function random_str( $cnt = 1000, $length = 8 ) {
$chars = array('a', 'b', 'c', 'd', 'e', 'f', 'g', 'h',
'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's',
't', 'u', 'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D',
'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O',
'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y','Z',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '!',
'@', '#', '$', '%', '^', '&', '*', '(', ')', '-', '_',
'[', ']', '{', '}', '<', '>', '~', '`', '+', '=', ',',
'.', ';', ':', '/', '?', '|');
$a = [];
for($j = 0; $j < $cnt; ++$j) {
$keys = array_rand($chars, $length);
$p = '';
for($i = 0; $i < $length; $i++) {
$p .= $chars[$keys[$i]];
}
$a[] = $p;
}
return $a;
}
最大内存使用情况:
function get_memory() {
$size = memory_get_peak_usage(true);
$mod = 1024;
$units = array('B', 'Kb', 'Mb', 'Gb');
$format = '%.2f%s';
for ($i = 0; $size > $mod; $i++) {
$size /= $mod;
}
return sprintf($format, round($size, 3), $units[$i]);
}
具体的测试代码大致是这样:
// 创建大小为10w的数组
$arr = random_str(100000);
$cnt = count($arr);
// 取1个出来判断
$search_arr = [];
for ($i=0; $i<1; ++$i) {
$r = rand(0, $cnt-1);
$search_arr[] = $arr[$r];
}
echo "----------- in_array -----------" . PHP_EOL;
$t0 = microtime(true);
for ($i=0; $i < 1; ++$i) {
if (in_array($search_arr[$i], $arr)) {
echo "";
}
}
echo "memory: " . get_memory() . PHP_EOL;
echo "time elapsed: " . (microtime(true) - $t0) . PHP_EOL;
上面是创建10w大小数组,取一个用 in_array() 来判断,同样地,其他的几个函数,把 in_array() 改一下就行,但是要注意的是:
isset() 和 array_key_exists() 使用数组的key来判断,所以需要多一步:将创建的数组的 key 和 value 用 array_flip() 对调一下,这一步也是要加入到统计中去的。
代码如下:
echo "----------- array_key_exists -----------" . PHP_EOL;
$t4 = microtime(true);
$key_arr = array_flip($arr);
echo "array_flip time elapsed : " . (microtime(true) - $t4) . PHP_EOL;
for ($i=0; $i<1; ++$i) {
if (array_key_exists($search_arr[$i], $key_arr)) {
echo "" ;
}
}
echo "memory: " . get_memory() . PHP_EOL;
echo "time elapsed: " . (microtime(true) - $t4) . PHP_EOL;
isset() 函数也是类似。
测试结果如下:

从图中可以看到, in_array 和 array_search 遥遥领先于另外两个,当 100w 数据时,前两个的执行速度 快了两个数量级 。内存方面, isset 和 array_key_exists 也是内存消耗大户,消耗的内存几乎是 in_array 和 array_search 的 1.5倍 。
仔细分析可以发现 isset 和 array_key_exists 其实并不慢,罪魁祸首是 array_flip() ,因为这两个函数都是通过 key 来判断的,所以我们需要把 value 转换成 key ,这就额外需要存储100w数据的空间,并且还要遍历把数据插入进去,可想而知是很耗内存和时间的。可以看如下截图:

整个执行时间 0.14150094985962 ,而 array_flip() 这个函数执行就花了 0.1414098739624 , isset 和 array_key_exists 本身是很快的。
如果要判断多个元素呢?是不是会降低 array_flip() 函数带来的影响?我们继续测试。
测试 100 个元素:

内存几乎没有变化,但执行时间 in_array 和 array_search 比后两个慢了几倍,变化得很明显,而 isset 和 array_key_exists 执行时间和查询2个元素几乎一致,查询的个数并不影响其效率,相反, in_array 和 array_search 的执行效率和个数成正比。
再来测试1000个:

在查询1000个的情况下,我等 in_array 和 array_search 这两个函数的结果已经不耐烦了,而 isset 和 array_key_exists 仍然很淡定,变化不大。
上面是对大字符串数组的测试,稍微做下调整来看看如果是连续的数字会是什么结果。
结果差不多,同样是查找1000个, array_key_exists() 函数花费了 0.028817176818848 , in_array() 函数仍然用了 1.4303638935089 。
为什么
那么为什么基于 key 的查询速度会快这么多呢?本着“不抛弃,不放弃”的原则,我查了下PHP中关于数组的实现,使用了 HashTable 。
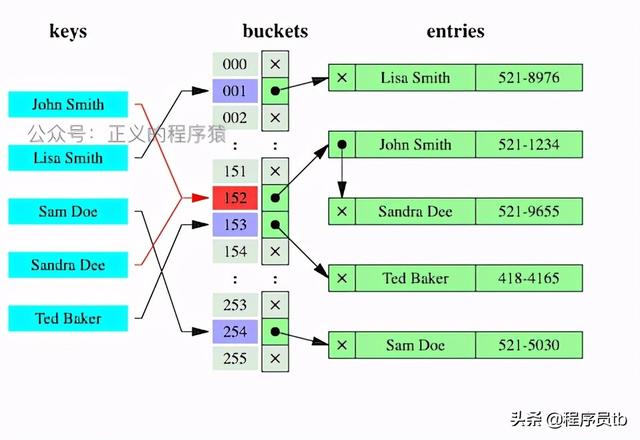
想必学校老师都已经教过吧(【算法与数据结构】复习起来),查找时通过 hash 函数计算元素索引,这个过程是很快的可以看作是 常量O(c) 的时间复杂度,所以就有了上面的测试结果, in_array() 和 array_search() 在查找时需要遍历整个数组,时间复杂度是 O(n) ,这当然慢咯,而通过 key 查找只要执行 hash 函数定位到索引,这速度肯定不是一个量级的。当然,鱼和熊掌不能兼得,通过 key 查找首先需要构造这样的数组,势必会降低效率还要消耗很多内存。
总结
在数据量少的情况下,建议使用 in_array 和 array_search 速度够快而且内存占用少,数据量特别大的时候,可以用 isset 和 array_key_exists ,同时也要考虑下内存的占用。
参考
#2484455
#Separate_chaining
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24