Apache SeaTunnel实现 非CDC数据抽取实践记录
目录
- 01 SeaTunnel简介
- 1. Apache SeaTunnel整体介绍
- 2. Apache SeaTunnel技术特性
- 3. Apache SeaTunnel工作流程
- 4. Apache SeaTunnel环境依赖
- 5. Apache SeaTunnel用户使用情况
- 02 SeaTunnel应用场景
- 1. 交管行业数据简介
- 2. 交管行业数据特点
- 03 相关业务痛点
- 1. 数据抽取限制较多
- 04 选择SeaTunnel的原因
- 1. SeaTunnel的优势
- 2. SeaTunnel的安装部署
- 3. SeaTunnel配置文件
- 4. SeaTunnel插件支持
- 05 具体实现方案
- 1. 数据增量更新具体实现
- 2. 具体方法
- 06 具体实现流程
- 1. 确定运算资源
- 2. 确定数据来源
- 3. 数据转换
- 4. 数据输出
- 5. 脚本和调度执行

导读: 随着全球数据量的不断增长,越来越多的业务需要支撑高并发、高可用、可扩展、以及海量的数据存储,在这种情况下,适应各种场景的数据存储技术也不断的产生和发展。与此同时,各种数据库之间的同步与转化的需求也不断增多,数据集成成为大数据领域的热门方向,于是SeaTunnel应运而生。SeaTunnel是一个分布式、高性能、易扩展、易使用、用于海量数据(支持实时流式和离线批处理)同步和转化的数据集成平台,架构于Apache Spark和Apache Flink之上。本文主要介绍SeaTunnel 1.X在交管行业中的应用,以及其中如何实现从Oracle数据库把数据增量导入数仓这样一个具体的场景。
今天的介绍会围绕下面六点展开:
- SeaTunnel简介
- SeaTunnel应用场景
- 相关业务痛点
- 选择SeaTunnel的原因
- 具体实现方案
- 具体实现流程
01 SeaTunnel简介
下面对SeaTunnel从产品功能,技术特性、工作流程、环境依赖、用户使用等方面做一个总体的介绍。
1. Apache SeaTunnel整体介绍
互联网行业数据量非常大,对性能还有其他各方面的技术要求都非常高,在笔者所在的交管行业中,情况就不太一样,各方面的要求也没有互联网行业那么高,在具体的数据集成应用中,主要是使用SeaTunnel1.X版本。
上图所示内容引用了Apache SeaTunnel官网中的介绍。
Apache Spark对于分布式数据处理来说是一个伟大的进步,但是直接使用Spark框架还是有一定门槛的,SeaTunnel这个产品把业界使用Spark的优质经验固化到了其中,明显降低了学习成本,加快分布式数据处理能力在生产环境中落地。在SeaTunnel2.X版本中,除了Spark,也增加了对Flink的支持。
除此之外,SeaTunnel还可以较好的解决实际业务场景中碰到的下列问题:
- 数据丢失与重复
- 数据集成中任务堆积与延迟
- 数据同步较低的吞吐量
- Spark/Flink应用到生产环境周期较长、复杂度较高
- 缺少应用运行状态的监控
2. Apache SeaTunnel技术特性

SeaTunnel具备如上图所示的技术特性:
- 简单易用,开发配置简单、灵活,无需编码开发,支持通过SQL进行数据处理和聚合,使用成本低
- 分布式,高性能,经历大规模生产环境使用和海量数据检验,成熟稳定
- 模块化和插件化,内置丰富插件,并且可以开发定制个性化插件,支持热插拔,具备高扩展性
- 使用Spark/Flink作为底层数据同步引擎使其具备分布式执行能力
3. Apache SeaTunnel工作流程
SeaTunnel的架构和整个工作流程如下图所示,Input/Source [数据源输入] -> Filter/Transform [数据处理] -> Output/Sink [结果输出],数据处理流水线由多个过滤器构成,以满足多种数据处理需求。如果用户习惯了SQL,也可以直接使用SQL构建数据处理管道,更加简单高效。目前,SeaTunnel支持的过滤器列表也在扩展中。
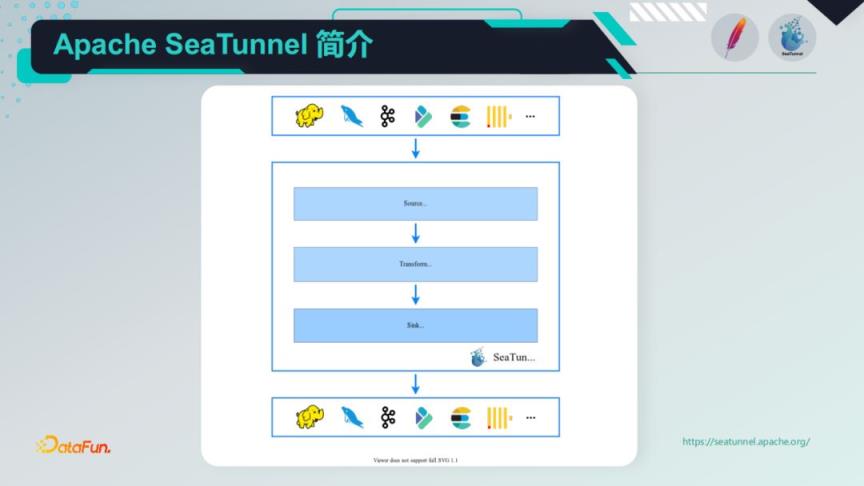
在插件方面,SeaTunnel已支持多种Input/Sink插件,同时也支持多种Filter/Transform处理插件,整体上基于系统非常易于扩展,用户还可以自行开发数据处理插件,具体如下:
- Input/Source 插件
Fake, File, Hive/Hdfs, Kafka, Jdbc, ClickHouse, TiDB, HBase, Kudu, S3, Socket, 自行开发的Input插件
- Filter/Transform 插件
Add, Checksum, Convert, Date, Drop数据转换
下图所示是必要的数据转换,在实际业务中,需要做一个过滤操作,取出大于最大更新时间的数据,convert插件里面做的是中间的一些数据类型转换操作,最后使用了一个sql插件,用于记录本次取到的数据的一www.cppcns.com个最大值,用于下次取数的比较。

4. 数据输出
下图所示的是数据处理后的输出,也就是output插件对应的配置,具体是把数据抽取到Clickhouse里面。然后数据集里面,那个更新列的最大值,通过追加模式,写回到HDFS中,供下次使用。

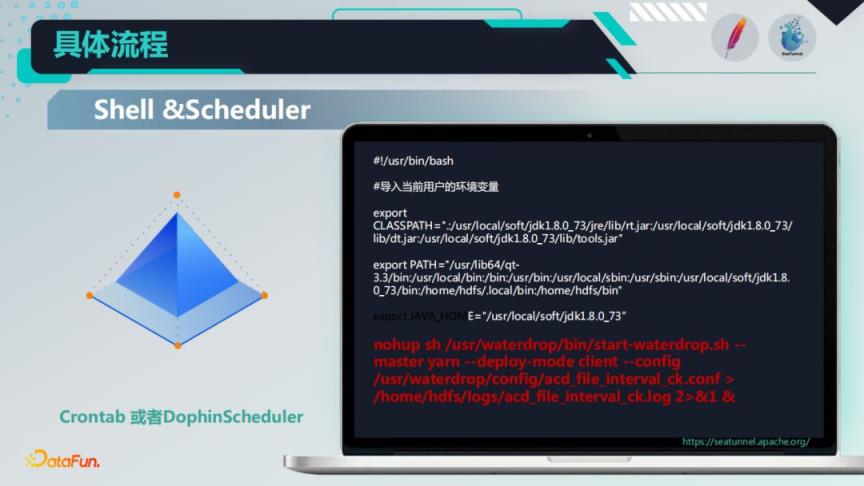
5. 脚本和调度执行
整个过程是通过下图所示的shell脚本来做的,通过nohup后台执行的方式,利用Crontab进行调度执行,因为在我们实际的业务中,对定时调度的要求不是很高,所以可以采用Crontab或者开源的Dolphin Scheduler都是可以满足的。
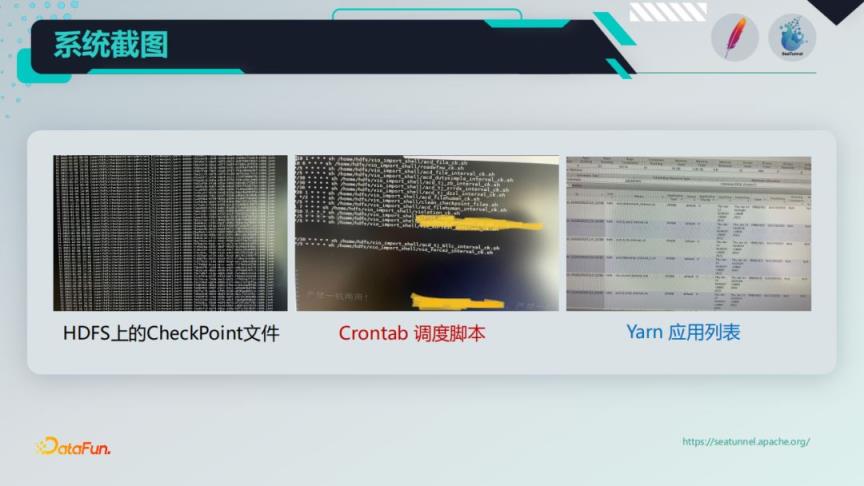
下面的截图,是实际运行过程中,产生在HDFS上的增量文件,Crontab调度脚本,以及执行过程中产生的一些Yarn任务列表。
在上述整体数据处理过程中,由于实际情况的限制,尤其我们的数据源是高度受限的Oracle数据库。但是对于很多传统公司,如果老系统是以Oracle为主,并且掌控力度比较大的话,现在想做数据架构升级,需要迁移Oracle中的数据,那么可以采用CDC读取日志或者触发器的方式,把数据变化写入到消息队列里面,通过SeaTunnel就可以很容易的把数据实时写入到其他异构的数据库。
到此这篇关于ApacheSeaTunnel实现非CDC数据抽取实践的文章就介绍到这了,更多相关ApacheSeaTunnel数据抽取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
热门文章

Linux怎样优化网络带宽使用
2025-04-20

如何手工制作台历?简单步骤与创意设计指南
2025-04-19

如何查询他人身份证号码?合法途径与注意事项解析
2025-04-19

Windows防火墙打不开怎么办?全面解决方法
2025-04-14

Linux设置环境变量的方法?linux设置环境变量的命令
2025-04-11

CentOS与Aliyun Linux有什么区别?如何选择最佳方案?
2025-03-24