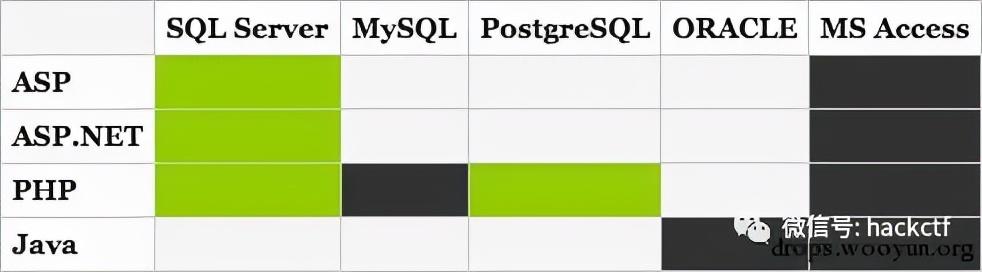
| 信用卡号(仅限 REGEXP): Visa: 4[0-9]{3}\s[0-9]{4}\s[0-9]{4}\s[0-9]{4}
MasterCard: 5[0-9]{3}\s[0-9]{4}\s[0-9]{4}\s[0-9]{4}
American Express: 37[0-9]{2}\s[0-9]{4}\s[0-9]{4}\s[0-9]{4}
Discover: 6011\s[0-9]{4}\s[0-9]{4}\s[0-9]{4}
| 匹配 (Visa): 4123 6453 2222 1746 非匹配 (Visa): 3124 5675 4400 4567, 4123-6453-2222-1746 同样,MasterCard 匹配一组 16 位的号码,以 5 开头,每四位号码组成的子集之间各有一个空格。American Express 和 Discover 是相同的,但是必须分别以 37 和 6011 开头。 |
| 日期(REGEXP 和 SIMILAR TO 均适用): ([0-2][0-9]|30|31)/(0[1-9]|1[0-2])/[0-9]{4}
| 匹配: 31/04/1999, 15/12/4567 非匹配: 31/4/1999, 31/4/99, 1999/04/19, 42/67/25456 |
| Windows 绝对路径(仅限 REGEXP): ([A-Za-z]:|\\)\\[[:alnum:][:whitespace:]!"#$%&'()+,-.\\;=@\[\]^_`{}~.]*
| 匹配:\\server\share\file 非匹配:\directory\directory2, /directory2 |
| 电子邮件地址(仅限 REGEXP): [[:word:]\-.]+@[[:word:]\-.]+\.[[:alpha:]]{2,3}
| 匹配:abc.123@def456.com, _123@abc.ca 非匹配:abc@dummy, ab*cd@efg.hijkl |
| 电子邮件地址(仅限 REGEXP): .+@.+\..+
| 匹配:*@qrstuv@wxyz.12345.com, __1234^%@@abc.def.ghijkl 非匹配:abc.123.*&ca, ^%abcdefg123 |
| HTML 十六进制颜色代码(REGEXP 和 SIMILAR TO 均适用): [A-F0-9]{6}
| 匹配:AB1234, CCCCCC, 12AF3B 非匹配:123G45, 12-44-CC |
| HTML 十六进制颜色代码(仅限 REGEXP): [A-F0-9]{2}\s[A-F0-9]{2}\s[A-F0-9]{2}
| 匹配:AB 11 00, CC 12 D3 非匹配:SS AB CD, AA BB CC DD, 1223AB |
| IP 地址(仅限 REGEXP): ((2(5[0-5]|[0-4][0-9])|1([0-9][0-9])|([1-9][0-9])|[0-9])\.){3}(2(5[0-5]|[0-4][0-9])|1([0-9][0-9])|([1-9][0-9])|[0-9])
| 匹配: 10.25.101.216 非匹配: 0.0.0, 256.89.457.02 |
| Java 注释(仅限 REGEXP): /\*.*\*/|//[^\n]*
| 匹配位于 /* 和 */ 之间的 Java 注释,或者前缀为 // 的一行注释。 非匹配:a=1 |
| 货币(仅限 REGEXP): (\+|-)?\$[0-9]*\.[0-9]{2}
| 匹配: $1.00, -$97.65 非匹配: $1, 1.00$, $-75.17 |
| 正数、负数和小数值(仅限 REGEXP): (\+|-)?[0-9]+(\.[0-9]+)?
| 匹配: +41, -412, 2, 7968412, 41, +41.1, -3.141592653 非匹配: ++41, 41.1.19, -+97.14 |
| 口令(REGEXP 和 SIMILAR TO 均适用): [[:alnum:]]{4,10}
| 匹配:abcd, 1234, A1b2C3d4, 1a2B3 非匹配:abc, *ab12, abcdefghijkl |
| 口令(仅限 REGEXP): [a-zA-Z]\w{3,7}
| 匹配:AB_cd, A1_b2c3, a123_ 非匹配:*&^g, abc, 1bcd |
| 电话号码(REGEXP 和 SIMILAR TO 均适用): ([2-9][0-9]{2}-[2-9][0-9]{2}-[0-9]{4})|([2-9][0-9]{2}\s[2-9][0-9]{2}\s[0-9]{4})
| 匹配: 519-883-6898, 519 888 6898 非匹配: 888 6898, 5198886898, 519 883-6898 |
| 句子(仅限 REGEXP): [A-Z0-9].*(\.|\?|!)
| 匹配:Hello, how are you? 非匹配:i am fine |
| 句子(仅限 REGEXP): [[:upper:]0-9].*[.?!]
| 匹配:Hello, how are you? 非匹配:i am fine |
| 社保号码(REGEXP 和 SIMILAR TO 均适用): [0-9]{3}-[0-9]{2}-[0-9]{4}
| 匹配: 123-45-6789 非匹配:123 45 6789, 123456789, 1234-56-7891 |
| URL(仅限 REGEXP): (http://)?www\.[a-zA-Z0-9]+\.[a-zA-Z]{2,3}
| 匹配:http://www.sample.com、www.sample.com 非匹配:http://sample.com, http://www.sample.comm |