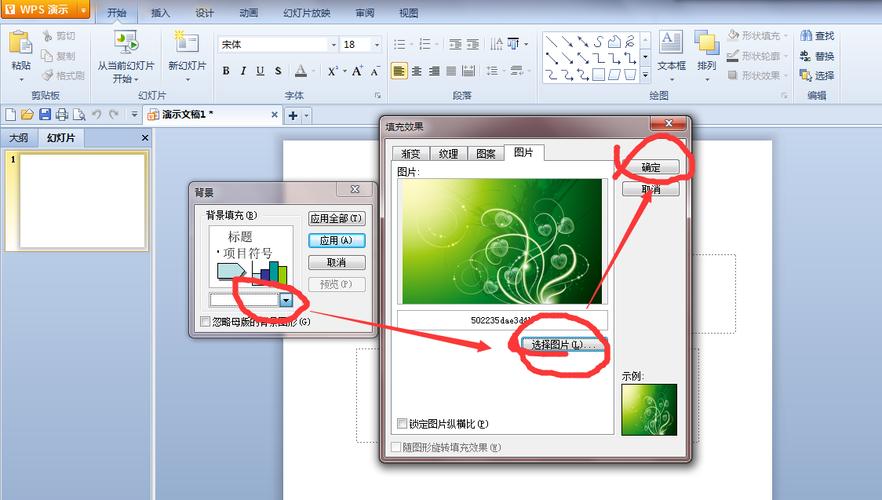
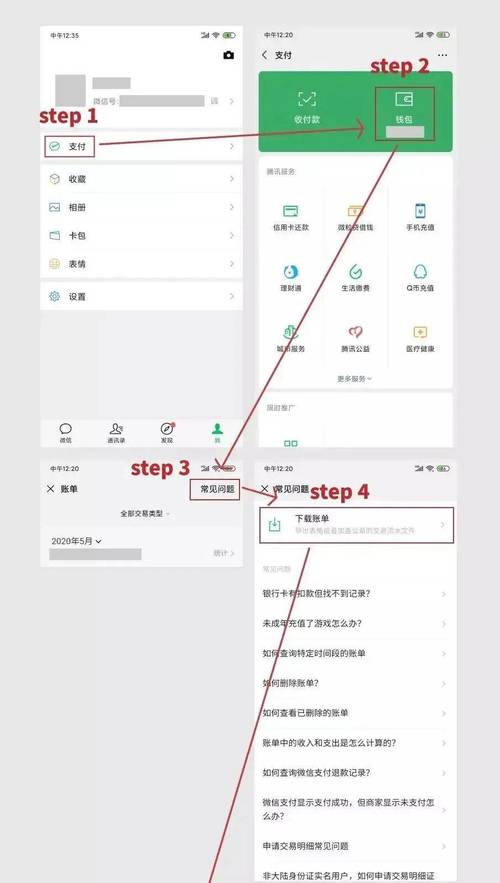
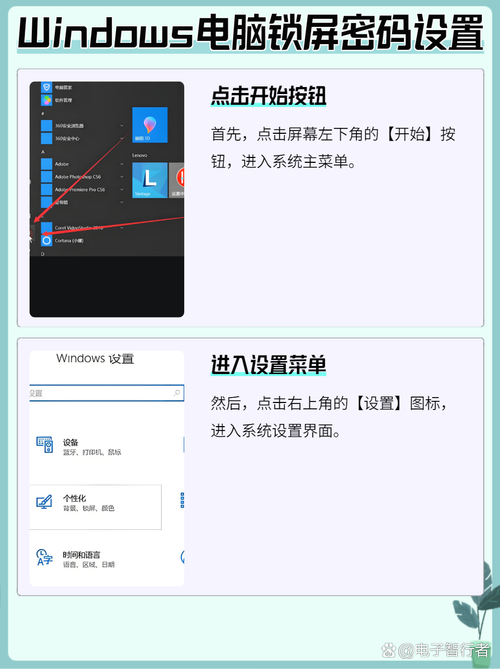
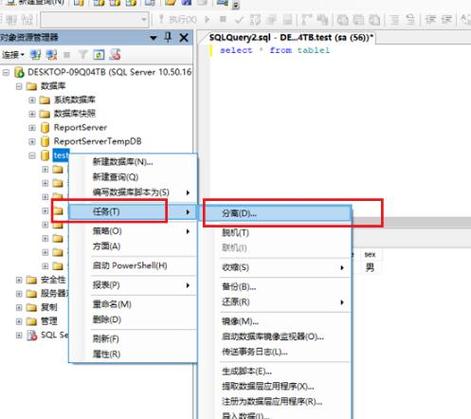
基于VIP的Keepalived 高可用架构是怎么样的
发布于 2021-12-23 21:18:18
上一篇:在flink中如何进行keyby窗口数据倾斜的优化 下一篇:keil4+proteus 51如何实现单片机点亮led灯
目录