如何解决Kafka 503报错?
Kafka服务不可用?深入解析503错误与应对策略
Apache Kafka作为分布式消息系统的核心组件,其稳定性直接影响数据流水线的健康度,当控制台或日志中出现"Error 503: Service Unavailable"提示时,意味着生产者或消费者无法与Broker建立有效连接,这种报错并非单一因素导致,通常涉及网络层、资源分配及集群配置等多维度问题。
503错误的三大核心诱因
-
网络分区与防火墙拦截 集群节点间心跳检测超时可能导致Broker被临时踢出ISR列表,检查防火墙规则是否开放9092(默认生产端端口)或9093(SSL加密端口),同时验证安全组策略是否允许跨节点通信,云环境中的VPC配置错误是常见触发因素。
-
资源耗尽引发的连锁反应
- 内存溢出:Broker的JVM堆内存不足时,垃圾回收器会进入频繁STW状态,无法及时处理请求
- 文件描述符限制:Linux系统默认的1024文件句柄数无法支撑高并发场景,需调整至65535以上
- 磁盘空间告急:Log.dirs指向的存储目录使用率超过95%时,Broker会自动停止接收新消息
-
控制器(Controller)选举异常 ZooKeeper集群状态不一致会导致Controller节点反复选举,期间所有分区元数据请求将返回503,可通过
kafka-topics.sh --describe观察Leader副本显示"-1"确认该问题。
精准诊断五步法
-
监控看板优先检查 关注Broker节点的CPU负载、网络IOPS以及Under Replicated Partitions数量波动,若发现副本同步延迟持续增长,往往预示集群处于亚健康状态。
-
服务端日志深度排查 使用
grep "503\|UNAVAILABLE" kafka/server.log过滤错误日志,重点关注WARN级别以上的异常堆栈,常见关键信息包括: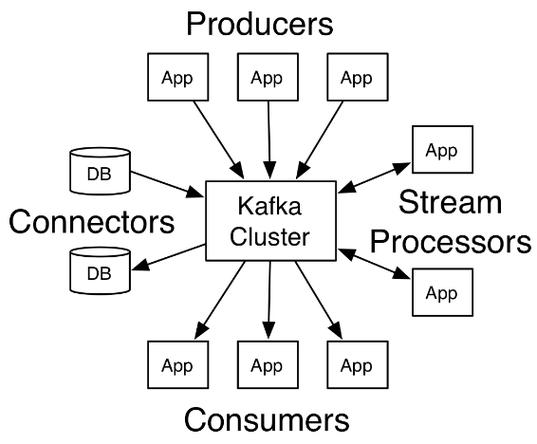
- "Not enough replicas available" 表示副本不足
- "NetworkThread expired" 指向网络线程阻塞
-
客户端连接测试 通过telnet验证基础连通性:
telnet broker-ip 9092,若连接失败,需从操作系统层面检查端口监听状态(netstat -tulnp | grep 9092)。 -
生产者端容错验证 临时调整生产者配置:
acks=1和retries=3,观察是否缓解问题,注意高版本Kafka建议使用delivery.timeout.ms替代旧版重试参数。 -
控制器健康度检测 执行
zookeeper-shell.sh zk-host:2181 get /controller获取当前Controller节点ID,核对该Broker是否处于正常运行状态。
长效防治体系构建
-
资源预留策略 为JVM堆内存设置监控告警阈值,建议保留25%的物理内存余量,使用
-XX:MaxGCPauseMillis=200参数控制垃圾回收停顿时间。 -
副本放置优化 跨机架部署分区副本,避免单点故障,通过
broker.rack参数配置机架感知,确保副本分布在不同物理设备。
-
客户端重试机制 配置渐进式回退重试策略:
retry.backoff.ms=100配合retry.backoff.max.ms=30*1000,实现指数级退避避免雪崩效应。 -
监控体系强化 部署Prometheus+Grafana监控平台,重点跟踪以下指标:
kafka_server_brokertopicmetrics_request_total请求吞吐量kafka_network_processor_avg_idle_percent网络线程空闲率kafka_controller_controllerstats_leader-election-rate领导者选举频次
实际运维中,503错误往往是系统承载边界的重要信号,建议建立容量规划机制,当集群吞吐量达到理论值的70%时启动扩容流程,通过蓝绿部署方式逐步替换老旧节点,避免业务中断,稳定的Kafka集群不是配置出来的,而是通过持续监控、调优迭代出来的有机体系。