怎么在Kubernetes部署期间正确处理DB模式
发布于 2022-01-14 22:31:50
上一篇:部署SaaS系统的好处有哪些 下一篇:如何配置hadoop基础编译环境
目录
推荐阅读
-
Linux如何在命令行下创建和管理 Kubernetes 命名空间
-
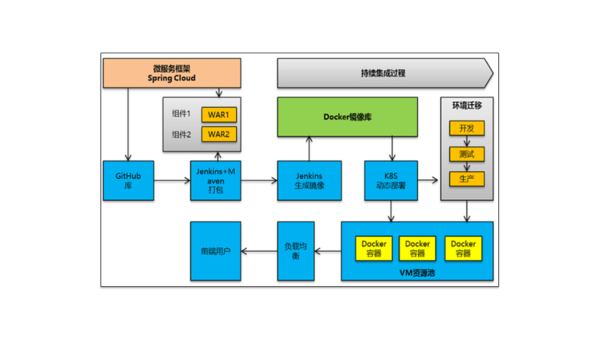
容器化最佳实践:Docker 与 Kubernetes 在微服务架构中的协同设计
-
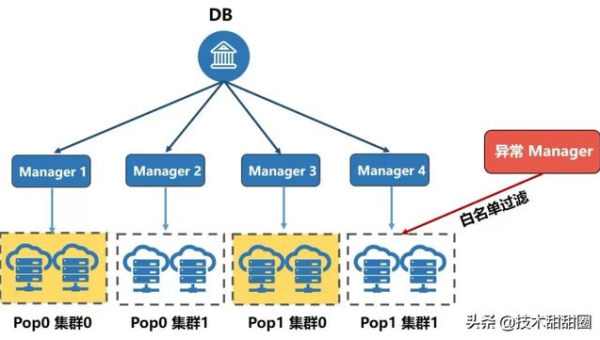
Kubernetes 集群部署避坑:资源调度、服务发现与滚动更新策略
-
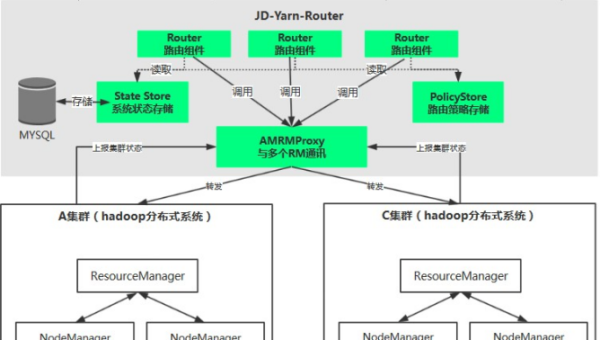
Kubernetes 自定义资源定义(CRD):扩展集群功能的进阶玩法
-
Node.js 微服务部署:通过 Kubernetes 实现自动扩缩容与负载均衡
-
Kubernetes 调度算法解析:资源分配策略与节点亲和性配置
-
Kubernetes Pod 启动失败?容器日志分析与资源配额检查步骤
-
Docker Desktop 4.20 新特性:Kubernetes 集成增强与资源监控优化
-
容器编排工具选型:Kubernetes vs Docker Swarm vs Rancher
-
Kubernetes 服务发现解析:DNS 与 Endpoint 切片的原理与配置