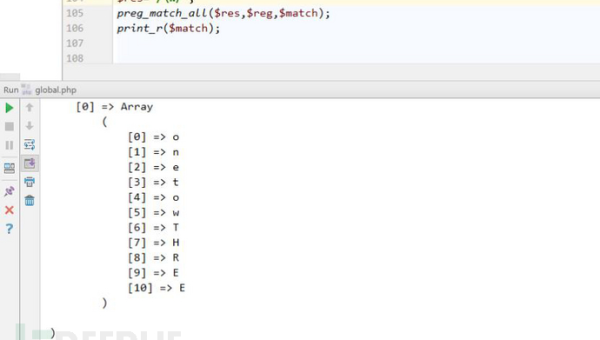
数据提取时用xpath还是正则表达式呢
发布于 2021-12-29 23:24:34
上一篇:正则表达式在ios中怎么用 下一篇:如何利用正则表达式提取出由三维软件导出的STL文件中的顶点数据
目录