python中dropna()函数的语法及示例代码详解
近期有些网友想要了解python中dropna()函数的语法及示例代码详解的相关情况,小编通过整理给您分析,同时介绍一下有关信息。
在数据处理和分析的过程中,缺失值(NaN)是一个常见的问题。缺失值的存在不仅会影响数据分析的结果,还会导致某些操作无法正常执行。因此,处理缺失值是数据预处理中的一个重要环节。在Python的数据处理库Pandas中,dropna()函数提供了一种简单而有效的方式来删除含有缺失值的行或列。本文将详细介绍dropna()函数的语法及使用方法,并通过具体的示例代码帮助读者更好地理解和应用这一函数。
dropna()函数的语法如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
axis:可选参数,表示删除行还是列。默认值为0,表示删除包含缺失值的行;设置为1表示删除包含缺失值的列。how:可选参数,表示删除的条件。默认值为’any’,表示只要存在一个缺失值就删除整行或整列;设置为’all’表示只有当整行或整列都是缺失值时才删除。thresh:可选参数,表示在删除之前需要满足的非缺失值的最小数量。如果行或列中的非缺失值数量小于等于thresh,则会被删除。subset:可选参数,用于指定要检查缺失值的特定列名或行索引。inplace:可选参数,表示是否对原始数据进行就地修改。默认值为False,表示不修改原始数据,而是返回一个新的数据框。
下面是一些使用dropna()函数的示例:
importpandasaspd
#创建包含缺失值的数据框
data={'A':[1,2,None,4],
'B':[None,6,7,8],
'C':[9,10,11,12]}
df=pd.DataFrame(data)
#删除包含缺失值的行
cleaned_df=df.dropna()
#删除包含缺失值的列
cleaned_df=df.dropna(axis=1)
#只删除整行或整列都是缺失值的行或列
cleaned_df=df.dropna(how='all')
#至少需要2个非缺失值才保留行或列
cleaned_df=df.dropna(thresh=2)
#只在特定列中检查缺失值
cleaned_df=df.dropna(subset=['A','C'])
#在原始数据上进行就地修改
df.dropna(inplace=True)
这些示例展示了dropna()函数的不同用法,根据你的具体需求选择合适的参数设置。
附:Python丢弃含空值的行、列
创建DataFrame数据:
importnumpyasnp importpandasaspd a=np.ones((11,10)) foriinrange(len(a)): a[i,:i]=np.nan d=pd.DataFrame(data=a) print(d)
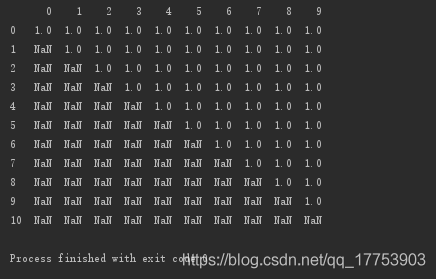
按行删除:存在空值,即删除该行
#按行删除:存在空值,即删除该行 print(d.dropna(axis=0,how='any'))
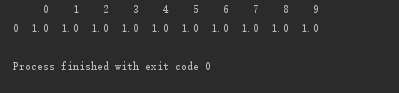
按行删除:所有数据都为空值,即删除该行
#按行删除:所有数据都为空值,即删除该行 print(d.dropna(axis=0,how='all'))
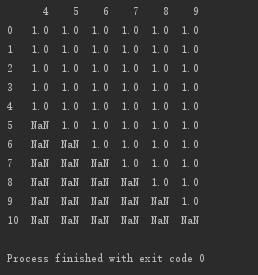
按列删除:该列非空元素小于5个的,即删除该列
#按列删除:该列非空元素小于5个的,即删除该列 print(d.dropna(axis='columns',thresh=5))
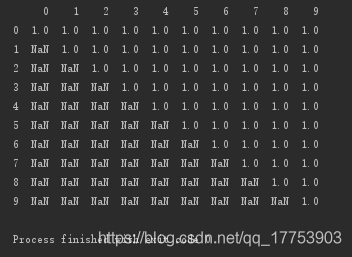
设置子集:删除第0、5、6、7列都为空的行
#设置子集:删除第0、5、6、7列都为空的行 print(d.dropna(axis='index',how='all',subset=[0,5,6,7]))
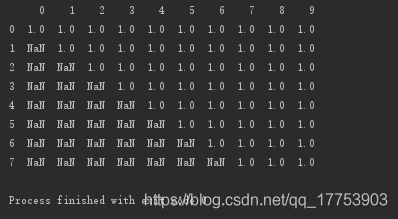
设置子集:删除第5、6、7行存在空值的列
#设置子集:删除第5、6、7行存在空值的列 print(d.dropna(axis=1,how='any',subset=[5,6,7]))
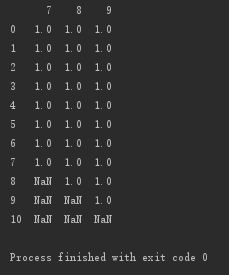
原地修改
#原地修改
print(d.dropna(axis=0,how='any',inplace=True))
print("==============================")
print(d)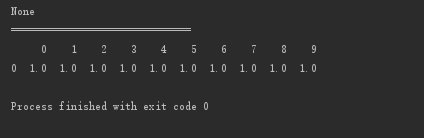
总结
通过本文的介绍,我们详细探讨了Pandas中dropna()函数的语法及使用方法。dropna()函数提供了多种参数选项,可以根据不同的需求灵活地删除含有缺失值的行或列。掌握这些参数的用法,不仅可以帮助我们更高效地处理缺失值,还能提升我们在数据预处理和分析中的整体能力。希望本文的内容能够对读者有所帮助,让大家在实际工作中能够灵活运用dropna()函数,解决数据处理的相关问题。
推荐阅读
-
Web应用从零开始,初学者友好型开发教程
-
容器化最佳实践:Docker 与 Kubernetes 在微服务架构中的协同设计
-
AWS Cloud9 使用攻略:云端 IDE 如何无缝集成 Lambda 与 S3 服务?
-
Heroku vs AWS Elastic Beanstalk:快速部署 Web 应用的平台对比
-
Kubernetes 集群部署避坑:资源调度、服务发现与滚动更新策略
-

Docker 镜像优化指南:分层构建、瘦身技巧与多阶段编译实践
-

Postman 接口测试全流程:从 API 设计到自动化测试脚本编写
-
pytest 框架进阶:自定义 fixture、插件开发与持续集成集成方案
-
JUnit 5 新特性:参数化测试、扩展模型与微服务测试实践
-
Chrome DevTools 性能分析:FPS 监控、内存快照与网络请求优化指南
