Python调用豆包API实现文档处理的实例详解
近期有些网友想要了解Python调用豆包API实现文档处理的实例详解的相关情况,小编通过整理给您分析,同时介绍一下有关信息。
在当今数据爆炸的时代,高效处理大规模文档成为企业和个人的重要需求。豆包大模型的API以其低廉的价格和强大的处理能力,为这一需求提供了有力的支持。本文将详细介绍如何在Linux服务器上配置和使用豆包大模型的API,以处理200万字的文档。通过具体的Python代码示例,我们将展示如何安装必要的库、设置API密钥,并调用API进行文档处理。
一、前言:
现在大模型api价格越来越便宜了,豆包大模型分为 lite 和 pro, 其中pro 32k 大模型的 api 价格在 0.0008元/千tokens,作为普通人能够用非常低的价格享受世界上最先进的科技,让我惊叹于技术的发展。
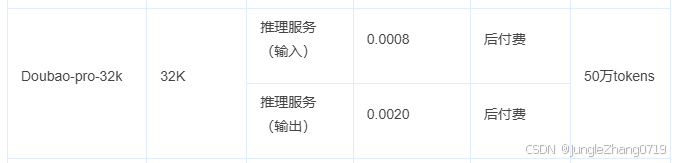
刚好手上有差不多200w字的文档要处理,我们这里选择 Doubao-pro-32k 的模型,换算成人民币差不多两块钱(再次震惊)。
备注:这篇文章要求一点点基础,这里默认你在 Linux 服务器上操作、已经有Conda 环境、Python 版本大于 3.7、会基础的 Linux 命令、并且看得懂简单的 Python代码。
二、配置环境
直接在 Windows 上安装豆包的库会报错:
note:Thiserrororiginatesfromasubprocess,andislikelynotaproblemwithpip. ERROR:Failedbuildingwheelforvolcengine-python-sdk Runningsetup.pycleanforvolcengine-python-sdk Failedtobuildvolcengine-python-sdk ERROR:Couldnotbuildwheelsforvolcengine-python-sdk,whichisrequiredtoinstallpyproject.toml-basedprojects
这是因为Windows 系统有最长路径限制,解决办法是自己看官方文档。我们这里还是以 Ubuntu 为例,在命令行输入:
pipinstall'volcengine-python-sdk[ark]'
从控制台获取api key:
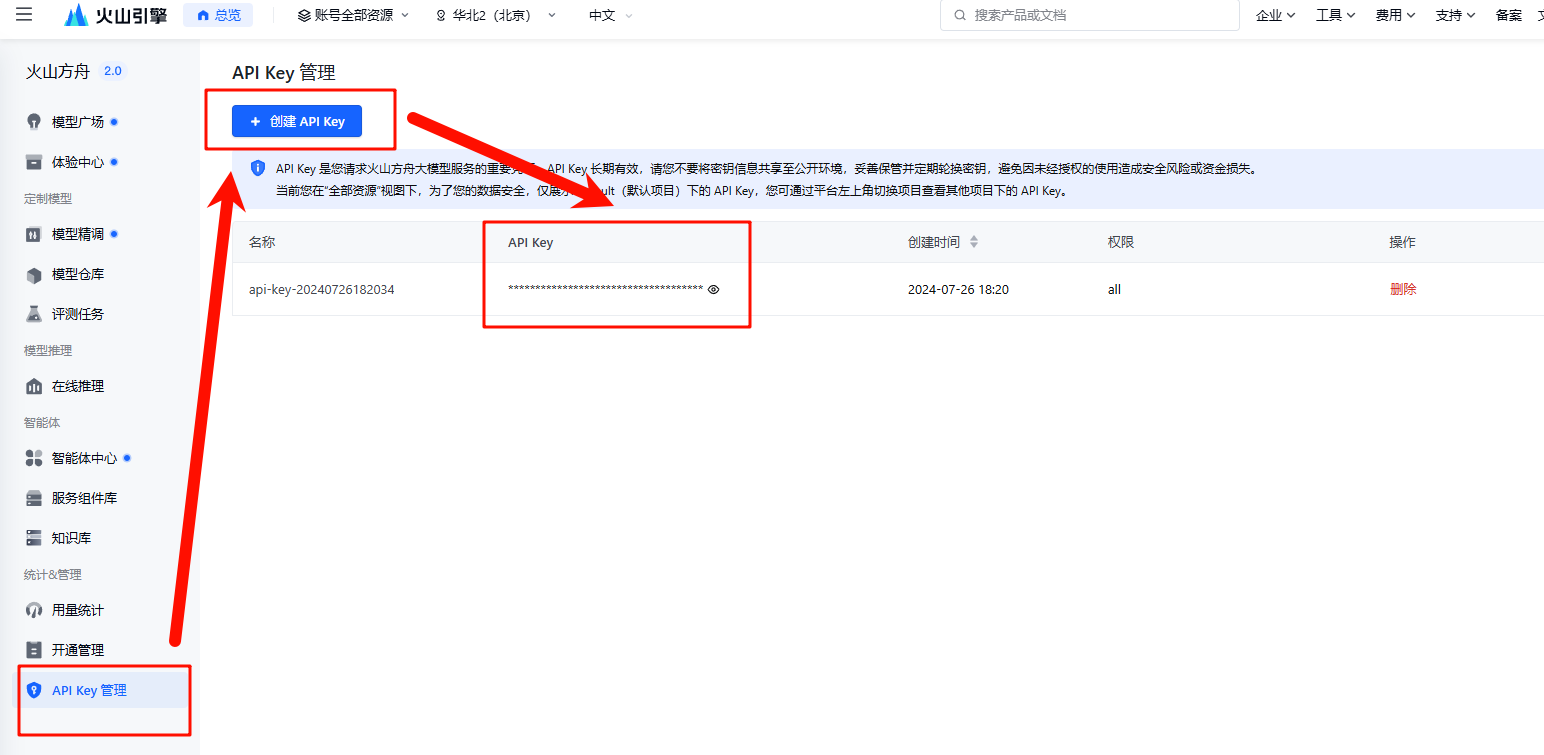
复制以后将 ARK_API_KEY 设置为全局变量,在命令行输入:
exportARK_API_KEY="你刚才创建的API-key"
然后我们去创建“模型推理接入点”:登录火山方舟平台,点击左侧导航栏中的【在线推理】,点击【 创建推理接入点 】。
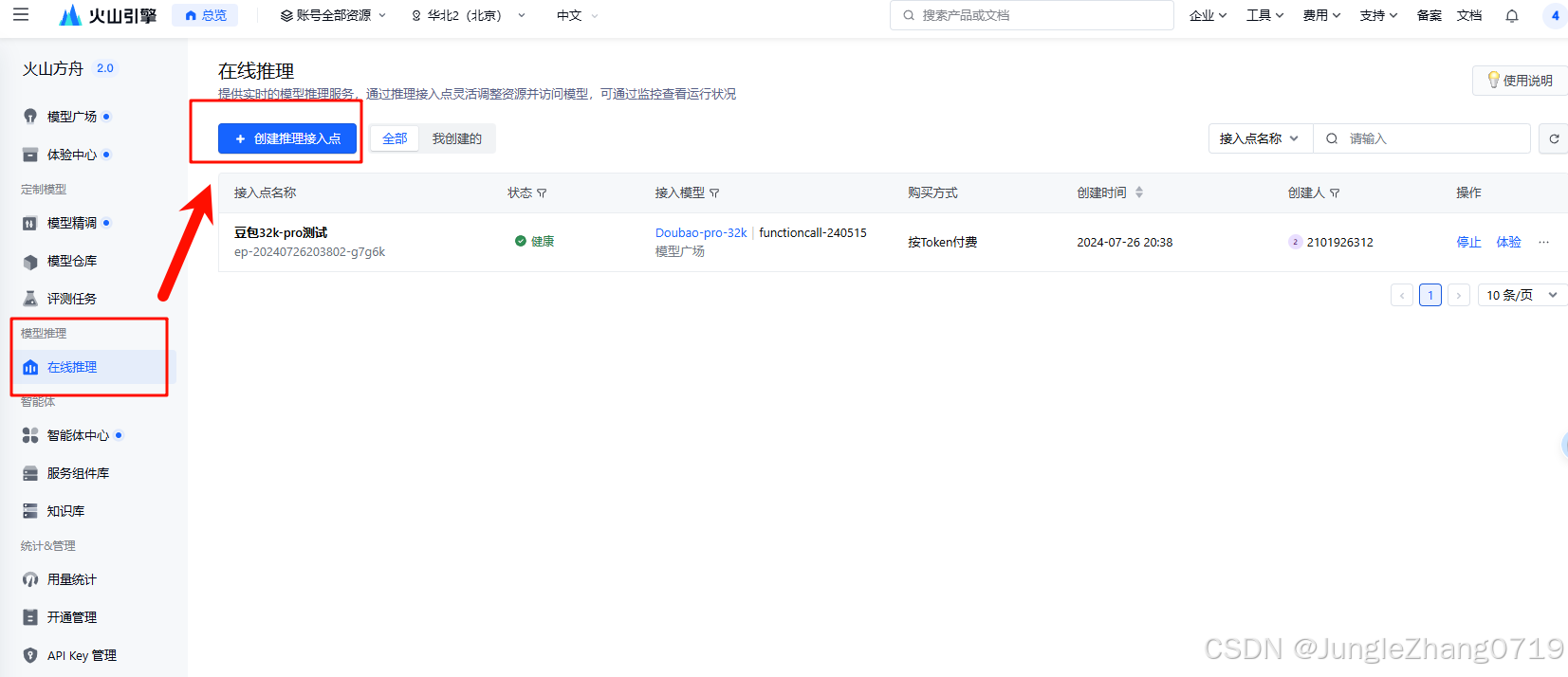
然后复制生成的ENDPOINT_ID
在命令行输入:
exportENDPOINT_ID="你的ENDPOINT_ID"
这样就完成了环境配置
三、调用 API
执行代码:
fromvolcenginesdkarkruntimeimportArk
importos
client=Ark()
print("-----standardrequest-----")
completion=client.chat.completions.create(
model=os.getenv('ENDPOINT_ID'),
messages=[
{"role":"system","content":"你是豆包,是由字节跳动开发的AI人工智能助手"},
{"role":"user","content":"常见的十字花科植物有哪些?"},
],
)
print(completion.choices[0].message.content)成功输出:
-----standardrequest----- 十字花科是一个较大的科,包含许多常见的蔬菜和花卉。以下是一些常见的十字花科植物: -**蔬菜**: -**白菜类**:包括大白菜、小白菜、菜心等。 -**甘蓝类**:如结球甘蓝(卷心菜)、羽衣甘蓝、抱子甘蓝等。 -**芥菜类**:有茎用芥菜(榨菜)、叶用芥菜(雪里蕻)、根用芥菜(大头菜)等。 -**萝卜类**:常见的有红萝卜、白萝卜、青萝卜等。 -**其他**:还有花椰菜(菜花)、西兰花、油菜、荠菜等。 -**花卉**: -**紫罗兰**:是十字花科紫罗兰属的二年生或多年生草本植物,花朵通常为紫色。 -**桂竹香**:属于十字花科桂竹香属,是一种多年生草本植物,花色丰富,有黄色、橙色、红色等。 -**诸葛菜**:又名二月兰,是十字花科诸葛菜属的一年或二年生草本植物,蓝紫色的花在每年的4-5月盛开。 -**香雪球**:是十字花科香雪球属的多年生草本植物,花朵小而密集,呈白色、淡紫色或紫红色。 这只是十字花科植物的一小部分,该科还包括许多其他的蔬菜和花卉。十字花科植物的特点是花朵呈十字形排列,果实为角果。这些植物在人们的生活中具有重要的经济和观赏价值。
参考:
https://www.volcengine.com/docs/82379/1263279
https://www.volcengine.com/docs/82379/1263482
总结
本文详细介绍了在Linux服务器上配置和使用豆包大模型API的方法,以处理大规模文档。通过安装volcengine-python-sdk库、设置API密钥和创建模型推理接入点,我们成功地调用了豆包大模型的API,并通过Python代码示例展示了其强大的文档处理能力。豆包大模型的API价格低廉,pro 32k 大模型的 api 价格仅为 0.0008元/千tokens,处理200万字的文档只需约两元。这使得企业和个人能够以极低的成本实现高效的文档处理,大大提升了工作效率。