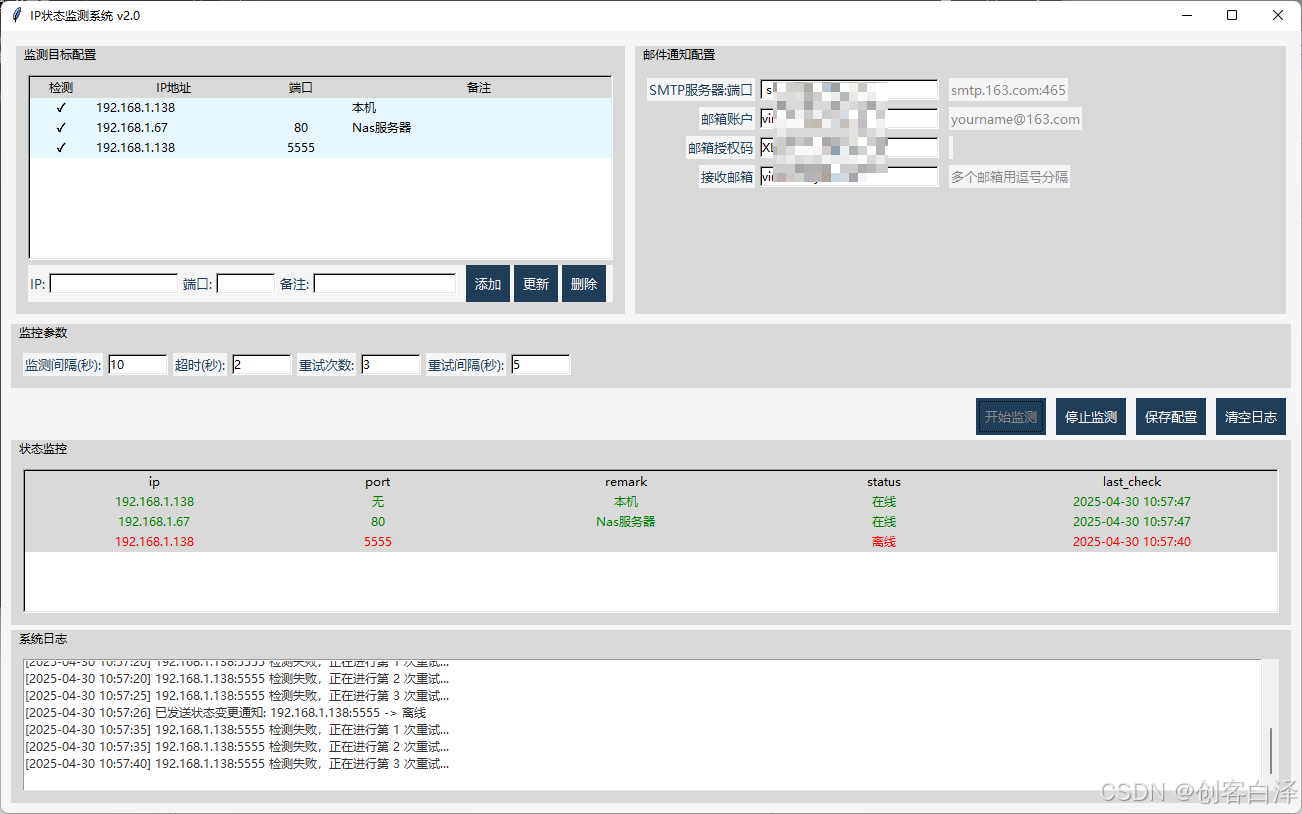
python中scrapy重复执行的实现方法
发布于 2021-05-30 14:09:11
上一篇:SpringBoot基于数据库如何实现定时任务 下一篇:html5中canvas微信海报分享的示例分析
目录